
Der grundlegende Data Science Workflow gibt eine ungefähre Struktur vor, wie man bei Data Science und Machine Learning Projekten vorgehen kann, um am Ende ein nutzbares Modell als Ergebnis zu haben. Es gibt verschiedene Ansätze für das Projektmanagement und die einzelnen Abschnitte bieten jeweils nur eine ungefähre Empfehlung in Bezug auf die Reihenfolge im Workflow. Dieser Artikel zeigt daher verschiedene Handlungsmöglichkeiten der einzelnen Phasen auf und ist keinesfalls als strikte Anweisung zu verstehen, alle Data Science Projekte zukünftig genau so zu gestalten. Je nach Art des Projekts und der damit einhergehenden Daten kann es auch sein, dass einzelne Phasen wegfallen oder nicht im Fokus der Arbeit stehen – auch das ist absolut denkbar. Mit diesem Artikel möchten wir also einfach einen Ratgeber zur Verfügung stellen, auf den bei Bedarf zurückgegriffen werden kann.
Die folgende Grafik visualisiert den allgemeinen Data Science Workflow, wie er im weiteren Verlauf des Beitrags genutzt und erläutert wird.
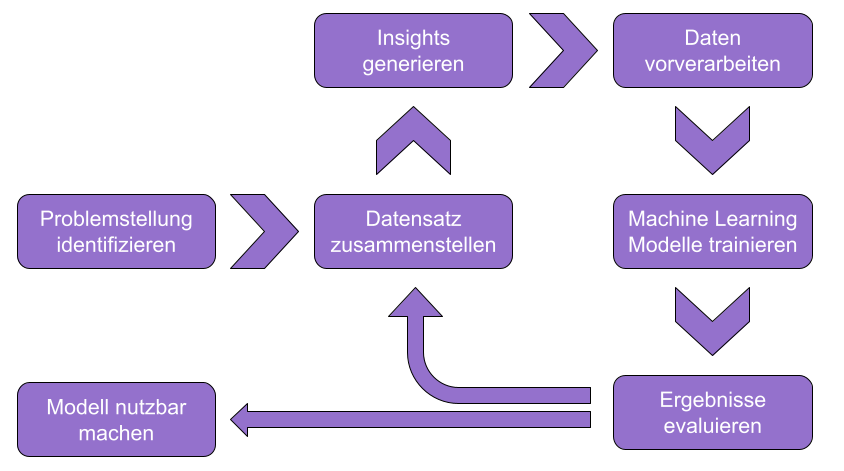
Problemstellung identifizieren #
Am Anfang eines Projekts steht immer, dass zunächst erst eine Problemstellung identifiziert wird, die gelöst werden soll. Damit einhergehend kann auch eine Zielsetzung formuliert werden, die optimalerweise in einem Satz festgehalten wird und wirklich nur das wesentliche beinhaltet. Eine Zielsetzung könnte bspw. sein:
“Auf Basis der Wetterprognose soll vorhergesagt werden können, wie viel erneuerbare Energie in der kommenden Woche produziert wird.”
Wenn das Ziel des Projekts klar ist, kann ein Projektplan aufgestellt und im Falle einer Gruppenarbeit die Zuständigkeit für einzelne Themen festgelegt werden.
Datensatz zusammenstellen #
Im zweiten Schritt liegt der Fokus auf den Daten, die zur Bearbeitung der Problemstellung erforderlich sind. Im Falle der oben genannten Zielsetzung wären das auf der einen Seite historische Wetterdaten und auf der anderen Seite die dazugehörige Produktion an erneuerbaren Energien. Generell stellt sich immer die Frage, ob die benötigten Daten bereits vorhanden sind oder ob eine Datenerhebung durchgeführt werden muss. Im Falle einer eigenen Datenerhebung gehen damit weitere Fragen einher, bspw. auf welche Details geachtet werden muss und wie genau das Setup aussehen soll. Ein wichtiger Punkte dabei ist je nach Art der Daten, dass das Aufnahme Setup einheitlich gehalten wird, um später vergleichbare Daten zu erhalten.
Der Datensatz wird meist im Laufe des Projekts erweitert bzw. überarbeitet, um die endgültigen Ergebnisse weiter zu verbessern. Generell gilt zwar häufig beim Machine Learning, dass ein größerer Datensatz zu besseren Ergebnissen führt – das gilt jedoch nur eingeschränkt und lässt sich nicht auf jede Problemstellung anwenden.
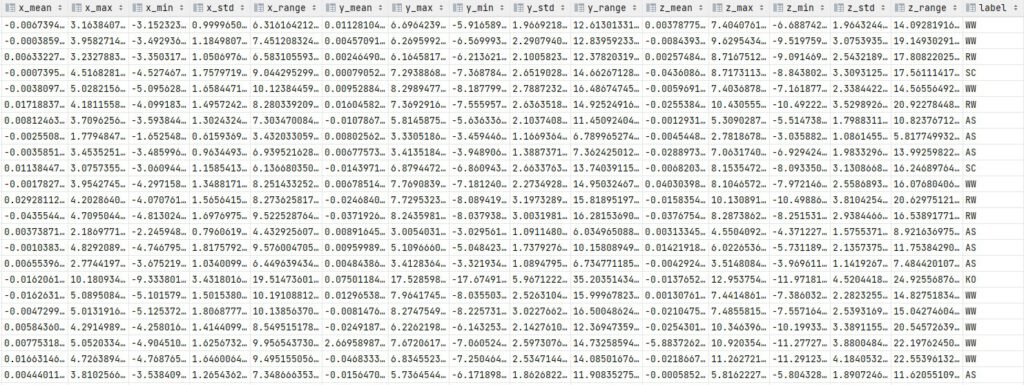
Eine weitere Fragestellung dieser Phase besteht darin, die Problematik der Datenspeicherung zu klären und ggf. die Dateibenennung festzulegen. Im Falle des Projekts “Untergrunderkennung beim Radfahren” wurden alle erhobenen Daten als CSV-Dateien gespeichert und nach einem einheitlichen Muster benannt, um bei weiteren Schritten einfacher mit den Daten arbeiten zu können. Die Datenspeicherung ist jedoch auch immer stark projektabhängig, daher gibt es nicht die eine Empfehlung.
Insights gewinnen #
Nachdem die ersten Daten vorliegen, gilt es ein gutes Datenverständnis aufzubauen und erste Insights aus den Daten zu gewinnen. Dabei ist es wichtig, auch Fachwissen entsprechend der Problemstellung aufzugreifen. Um erneut das Beispiel der Wetterprognose und den erneuerbaren Energien aufzugreifen, könnte man sich über die Effektivität von Windkraftanlagen bei verschiedenen Windstärken informieren und die Daten auf ersten Zusammenhänge hin untersuchen. Diese Phase inst generell auch als Data Exploration bekannt.
Generell sollte man sich immer die Frage stellen, mit welchen Daten man es zu tun hat, in welcher Form sie vorliegen und welche Eigenheiten sie ggf. haben, die in späteren Schritten beachtet werden müssen. Damit verbunden ist ebenfalls wichtig, dass alle Attribute beim Einlesen in Python den richtigen Datentyp erhalten und nicht bspw. numerische Werte als Text gespeichert werden.

Ein weiterer wichtiger Schritt sind erste Visualisierungen der Daten, um einen noch besseren Einblick zu bekommen. Das können unter anderem Verteilungen von numerischen Attributen oder Häufigkeiten bei kategorischen Attributen. Um eine sinnvolle Art der Visualisierung zu finden, kann die Seite Data-To-Viz genutzt werden.
Data Preprocessing #
Das Preprocessing dient dazu, die erhobenen bzw. vorhandenen Daten so umzuwandeln und aufzuräumen, sodass ein möglichst aussagekräftiger Datensatz entsteht. Je nach Form und Eigenschaft der Daten werden hierfür unterschiedliche Schritte benötigt. Bilder erfordern bspw. eine andere Vorverarbeitung als Daten eines Accelerometer-Sensors. Meist bestehend das Preprocessing aus den folgenden Schritten:
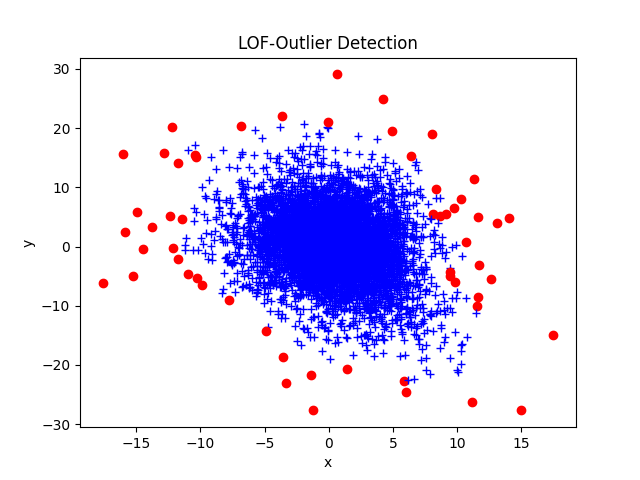
Im ersten Schritt dient die Outlier Detection dazu, falsche und ungültige Werte – sog. Ausreißer – zu erkennen und zu entfernen. Einerseits kann dies über domain knowledge erreicht werden (Beispiel: die Außentemperatur in Deutschland im Winter wird 30 °C nur sehr unwahrscheinlich überschreiten). Andererseits können statische Verfahren wie eine Distance Based Outlier Detection zum Einsatz kommen.
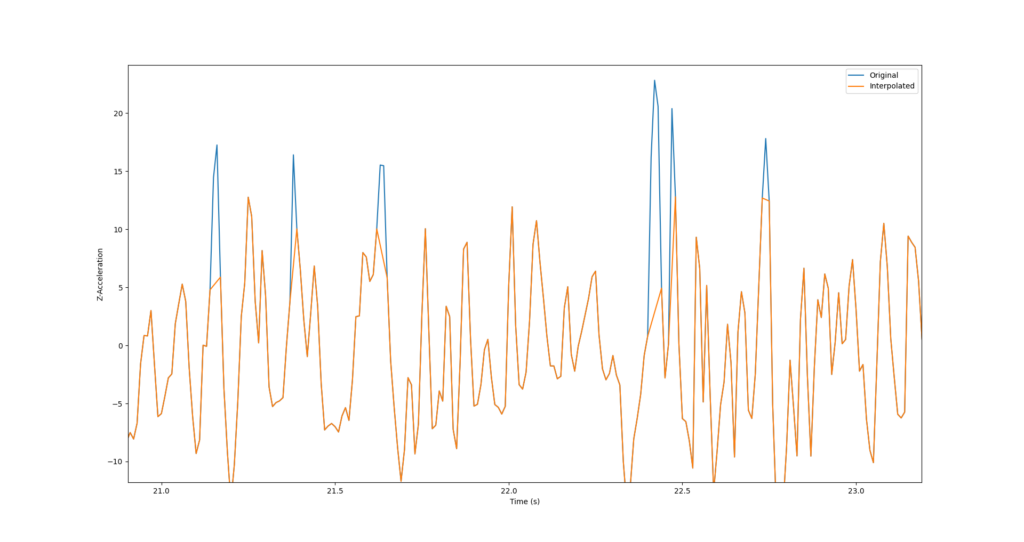
Durch die Value Imputation werden fehlende Werte durch neue, generierte Werte ersetzt. Fehlende Werte können zum Beispiel bei der Outlier Detection entstanden sein, oder sie fehlten bereits im Datensatz. Fehlende Werte können bspw. durch den Spaltenmittelwert des fehlenden Attributs ersetzt werden. Ein anderer Ansatz ist die Schätzung des fehlenden Werts mittels eines Clustering-Verfahrens unter Berücksichtigung aller anderen Attribute.
Sind nun zusammenhängende Daten vorhanden, werden ggf. weitere Verfahren, wie ein Lowpass-Filter, auf die Daten angewandt. Was genau verwendet wird, hängt stark vom Projekt ab. Abschließend werden aus den Rohdaten Features abgeleitet. Dies kann bedeuten, dass bestimmte Attribute umgewandelt werden, um zum Beispiel die Einheiten einer Messung zu vereinheitlichen (Scaling). Eine weitere Option ist die Principal Component Analysis (kurz PCA), mit der eine Dimensionsreduktion der bestehenden Daten erreicht werden kann. Möglicherweise müssen in einem letzten Schritt die Daten noch vervielfacht oder zurückgeschnitten werden, um ein ausgeglichenes Verhältnis der Klassen zu erhalten.
Machine Learning #
Nach dem Preprocessing kann mit dem Machine Learning begonnen werden. Hierfür wird zunächst ein Lernverfahren ausgewählt. Dieses sollte zu dem Problem passen, welches gelöst werden soll und gleichzeitig nicht zu komplex sein. Damit kann Zeit beim Training und im Betrieb gespart werden. Für eine Klassifikation mit wenigen Attributen ist eine Support Vector Machine möglicherweise völlig ausreichend, während für die Schätzung des Alters einer Person aus Bilddaten ein Convolutional Neural Network (CNN) angebrachter ist. Bei der Auswahl sollte auch beachtet werden, welche Modelle eventuell ungeeignet für das Problem sind.
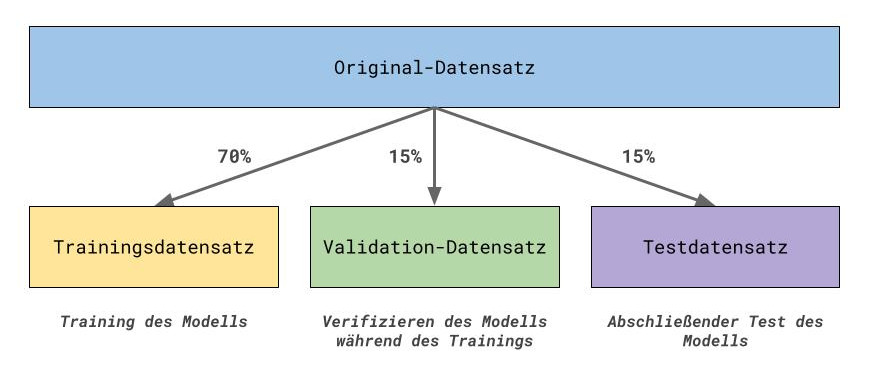
Vor dem Training des ausgewählten Modells wird der komplette Datensatz in zwei oder drei kleinere Datensätze aufgeteilt: 70% Trainingsdatensatz, 30% Testdatensatz. Der Testdatensatz wird manchmal noch halbiert in Validation- und Testdatensatz. Mit dem Trainingsdatensatz wird das Modell trainiert und anschließend mit dem Testdatensatz evaluiert.
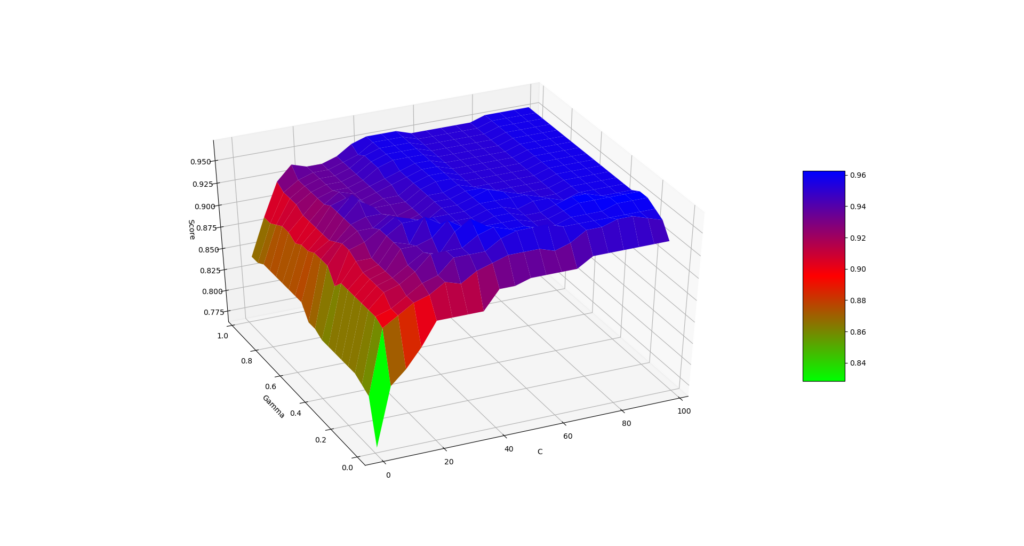
Um die Performance des Modell zu verbessern, können die Hyperparameter verändert werden. Hyperparameter sind Werte, die Eigenschaften des Modells bestimmen und bereits vor dem Training festgelegt werden müssen. Bei KNN müssen bspw. die Anzahl der zu betrachtenden Nachbar-Punkte definiert werden. Das Hyperparameter-Tuning sucht strukturiert oder nach dem Zufallsprinzip die besten Parameter für das Modell, sodass es eine möglichst gute Performance erbringt.
Evaluation der Ergebnisse #
Um die Performance eines Modells überhaupt bewerten zu können, muss zunächst auf Grundlage der Daten eine passende Metrik ausgewählt werden. Bei Regressions-Problemen können Mean-Squared-Error oder Mean-Absolute-Error genutzt werden, bei Klassifikations-Problemen Accuracy oder F1-Score. Bei der Auswahl ist bei der Klassifikation die Verteilung der Klassen zu beachten, um keine wenig aussagekräftige Ergebnisse zu erhalten wie etwa die Accuracy bei starker Class-Imbalance. Nach Auswahl der Metrik wird dann entweder über das Testset oder alternativ über Verfahren wie Cross-Validation berechnet. Auf Basis der Anforderungen, die mit der Problemstellung und der Zielsetzung einhergehen, kann dann entschieden werden, ob die Performance des Modells zufriedenstellend ist oder nicht. Entweder werden erneut die vorherigen Schritte durchlaufen, um die Performance zu verbessern, oder alternativ kann mit der abschließenden Deployment Phase begonnen werden.
Deployment des Modells #
In der letzten Phase des Data Science Workflows geht es darum, das endgültige Modell nutzbar zu machen. Dafür sollte zunächst die Laufzeitumgebung des Modells geklärt werden, wie etwa innerhalb von Python-Scripts, in Webanwendungen, auf dem Smartphone, in Cloud basierten Anwendungen, oder auf Abruf über eine API. Das Modell kann dann in die entsprechende Form gebracht (z.B. TensorFlow-Lite Modell bei mobilen Anwendungen) und in das System integriert werden. Immer mehr Anbieter, wie Amazon Web Services oder auch Google, stellen die Möglichkeit zur Verfügung, Machine Learning Modelle direkt in cloudbasierte Prozesse zu integrieren und diese damit zu optimieren. Ein denkbarer Usecase wäre z.B. ein Modell zur Schätzung der Kreditwürdigkeit eines Kunden. Sobald sich ein neuer Kunde registriert, berechnet das Modell automatisch seinen Score, ohne dass manuell ein Prozess gestartet werden muss.
Zwischen finalem Training eines Modells und der tatsächlichen Nutzung des Modells liegen meist ein paar Monate (natürlich abhängig vom Projekt), da für die optimale Nutzung in vielen Fällen Prozesse angepasst und optimiert werden müssen.



