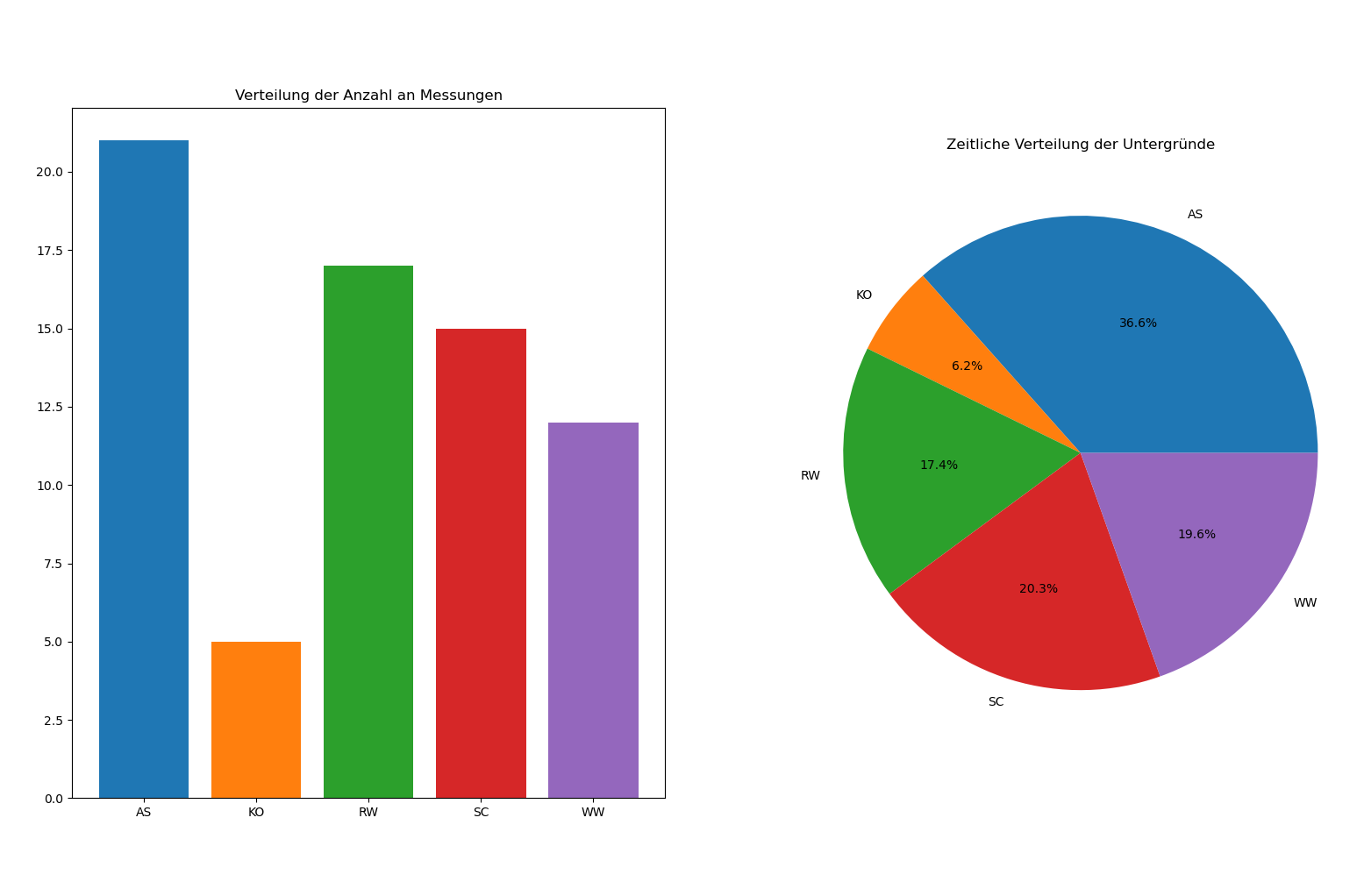
In diesem Schritt werden die Beschleunigungsdaten jeweils am Anfang und am Ende der Messung geschnitten, um so das anfängliche Anfahren und das abschließende Abbremsen des Fahrrades aus den Messdaten zu entfernen. Es wird also ein Offset von den Daten abgezogen, um irrelevante Daten zu löschen. In unserem Projekt werden die Trainingsdaten für das Machine Learning mit manuellen Offsets verarbeitet, um eine optimale Trainingsgrundlage zu schaffen. Im Anschluss daran geschieht das Testen des Modells mit einem vordefinierten Offset von zehn Sekunden.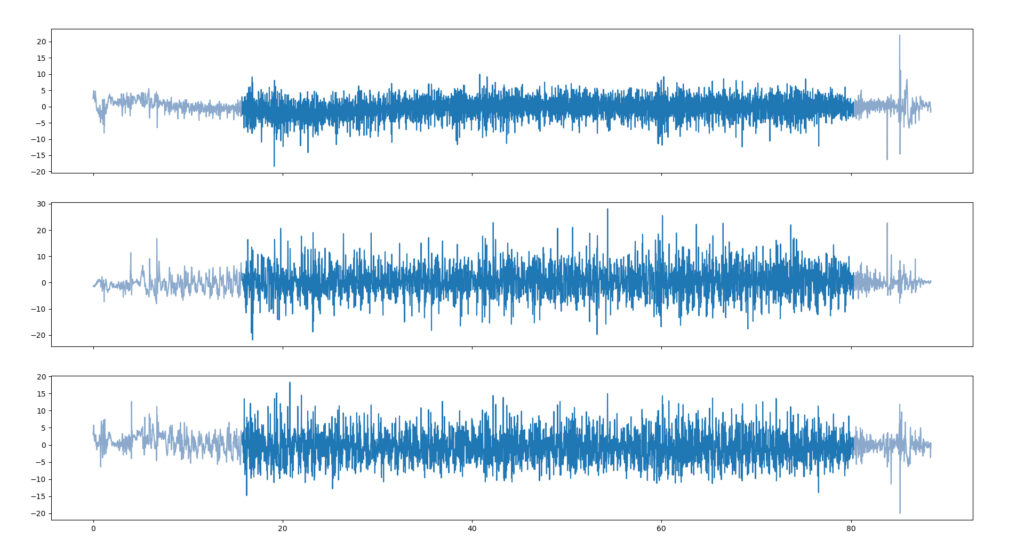
Im nächsten Schritt der Datenverarbeitung wird die Herausforderung der verschiedenen Fahrräder und damit verbundenen Federungen gelöst. Zunächst wurde diese Problematik vernachlässigt, wodurch jedoch die Schritte des Feature Engineerings und des Machine Learnings nicht die erwünschten Ergebnisse brachten. In der Analyse von zwei Asphalt Samples, die zeitgleich auf der gleichen Strecke mit verschiedenen
Fahrrädern aufgenommen wurden, fielen deutliche Unterschiede in den gemessenen Beschleunigungen auf. Das lässt sich mit den unterschiedlichen Federungen der beiden Fahrräder erklären. Federungssysteme sind darauf ausgelegt, Energie der Umwelt (z.B. Unebenheiten) aufzunehmen und damit die Fahrt angenehmer zu machen. Wenn ein Fahrrad mehr gefedert ist, wird mehr Energie aufgenommen. Damit zusammenhängend wirkt eine geringere Kraft auf den Fahrer und der Beschleunigungssensor in der Hosentasche nimmt geringere Beschleunigungen auf. Um dieses Problem zu lösen und die Daten vergleichbar zu machen, wird der Federungskoeffizient (engl. suspension coefficient, kurz SPC) eingeführt. Dabei werden Daten vom ungefederten Fahrrad als Referenz angenommen und Messungen von gefederten Fahrrädern werden über den Koeffizienten auf ein ähnliches Niveau angehoben. Der Koeffizient wird nicht direkt als Faktor, sondern in der Form processed_data = raw_data / (1 – coefficient) auf die Daten angewandt. Das heißt bei einem Koeffizienten von null bleiben die Daten unverändert. Die Abbildung zeigt den tatsächlichen Faktor, der einem Koeffizienten entspricht.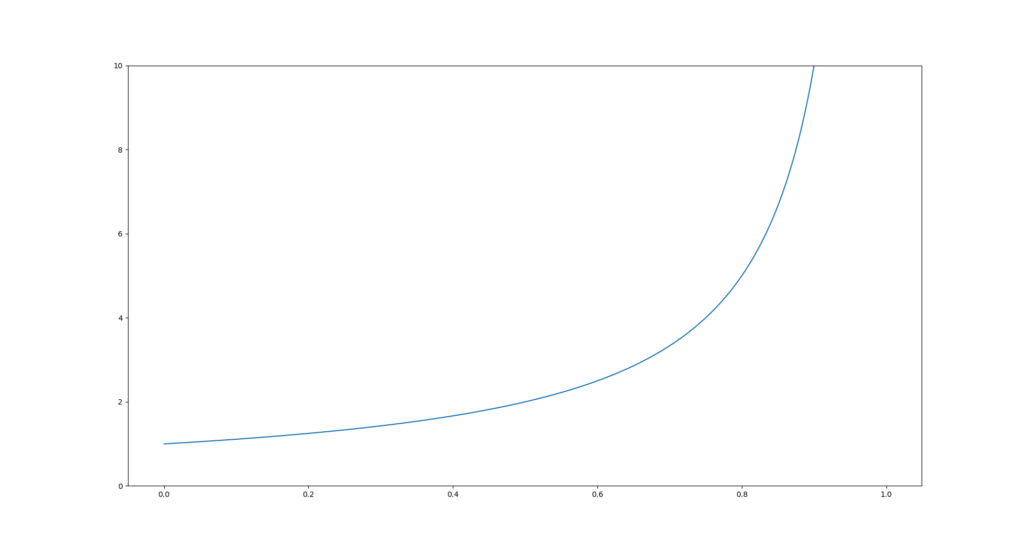
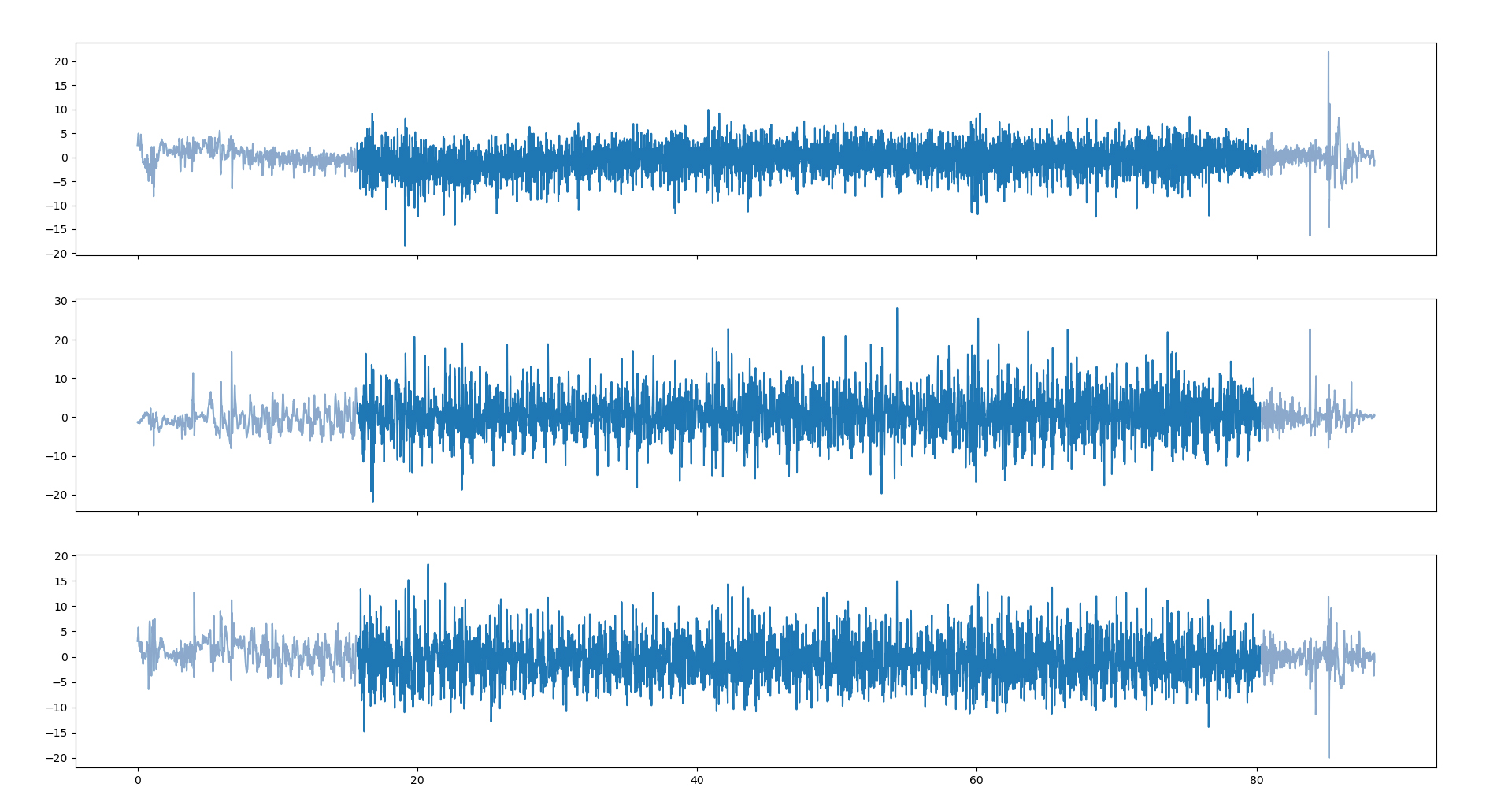
Durch die Aufnahme der Daten mit dem Smartphone in der Hosentasche ist die Tretbewegung beim Fahren deutlich in den Daten zu erkennen.
Unterschiedliche Fahrer treten mit verschiedenen Frequenzen und auch während der Fahrt kann diese z. B. durch Schaltvorgänge stark schwanken. Die Tretbewegung liegt in einem Frequenzbereich von 0 bis 2 Hz bzw. 0 bis 120 U/min. Des weiteren soll das Grundrauschen des Sensors aus dem Signal entfernt werden, da dies ungewollte Effekte bei der Verarbeitung durch Machine Learning Modelle haben könnte. Die verwendeten Beschleunigungssensoren arbeiten mit einer Frequenz von 100 Hz bzw. 200 Hz. Da die Obergrenze unterhalb der halben Abtastfrequenz liegen muss, um überhaupt eine Auswirkung zu haben, haben wir uns für eine Obergrenze von 30 Hz entschieden, denn bei einer Abtastfrequenz von 100 Hz kann die höchste gemessene Frequenz max. 50 Hz betragen. Jedoch sollte sie auch nicht zu niedrig gewählt werden, da sonst Details der Messung verloren gehen, die eine Aussage über den befahrenen Untergrund geben könnten. Um die nicht gewünschten Frequenzbänder aus dem Signal zu entfernen, wird ein Bandpass-Filter verwendet. Die Abbildung zeigt die Daten vor und nach dem Filter.
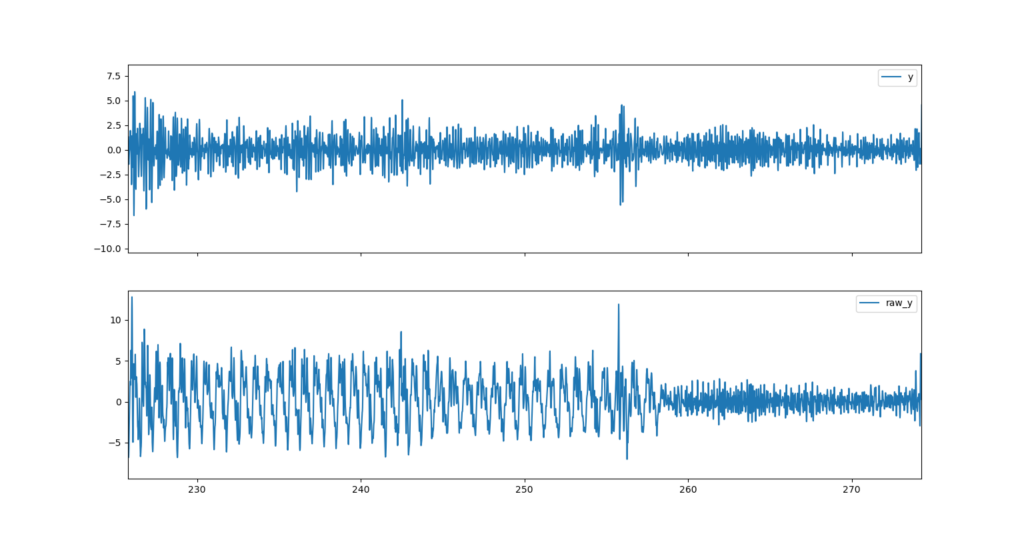
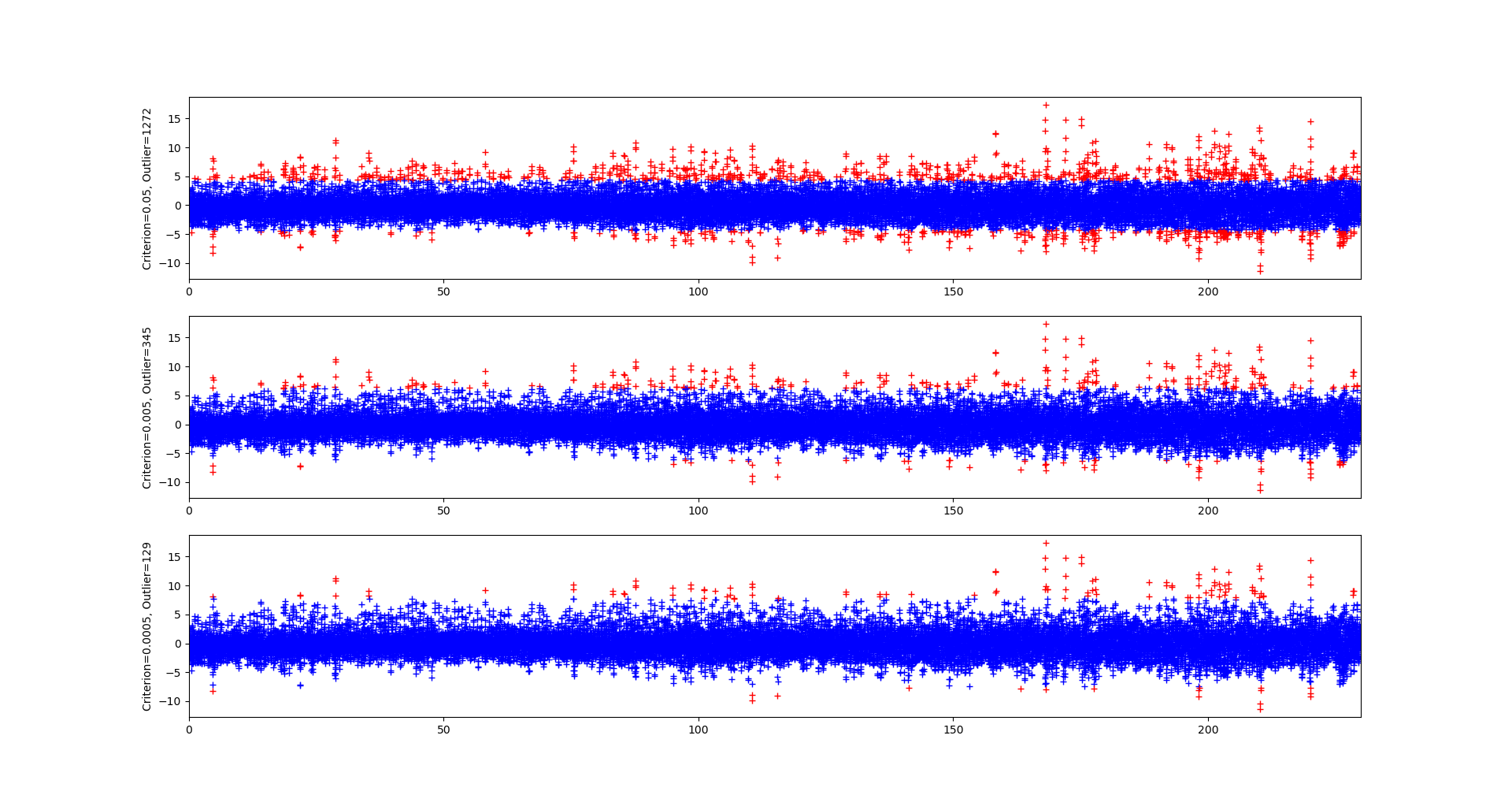
Während der Aufnahme von Beschleunigungsdaten werden nicht nur für das Machine Learning relevante Untergrunddaten erfasst, sondern auch unerwünschte Ausreißer, die z.B. durch Schlaglöcher im Asphalt oder Stöcke auf einem Fahrradweg entstehen. Diese gilt es aus den Datensätzen zu entfernen, da sie die weitere Verarbeitung verfälschen. Als Ausreißer werden allgemein Datenpunkte bezeichnet, die sich vom Großteil der restlichen Daten unterscheiden und Werte weit entfernt des Durchschnitts annehmen. Mithilfe einer Outlier Detection (zu Deutsch: Ausreißererkennung) werden eben diese Datenpunkte erkannt und können anschließend entfernt werden. Für unsere Datenverarbeitung haben wir uns für eine verteilungsbasierte Outlier Detection entschieden. Dabei wird angenommen, dass Daten einer Messung um den Mittelwert herum normalverteilt sind. Daraus ergibt sich für Datenpunkte eine Wahrscheinlichkeit, dass sie zu dieser Normalverteilung gehören. Über das
Chauvenet-Kriterium kann eine Grenze festgelegt werden, ab der Datenpunkte als Ausreißer behandelt werden. Je nachdem, wie hoch das Kriterium angesetzt wird, ändert sich die Anzahl der erkannten Ausreißer. Die Abbildung visualisiert diesen Zusammenhang.