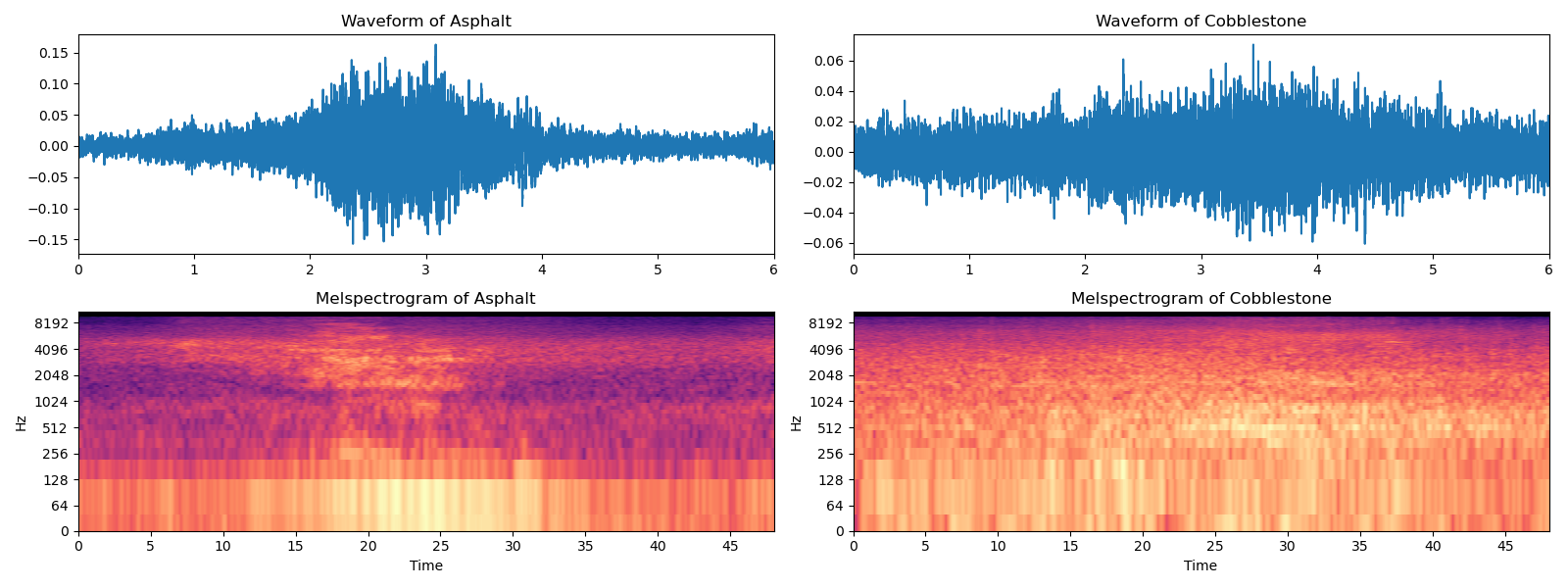
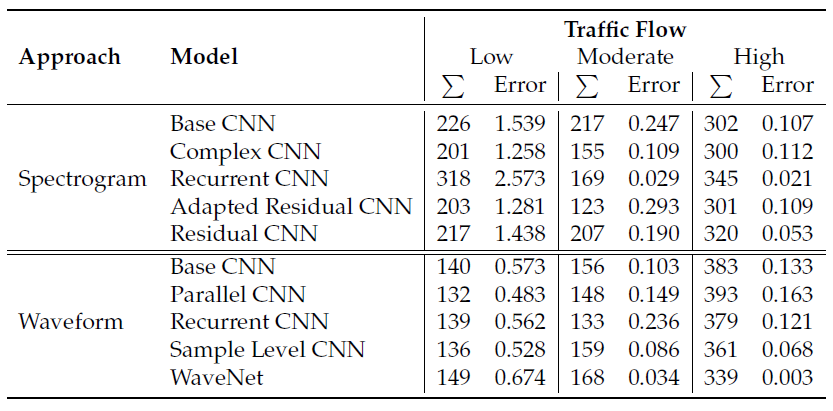
Der erste Schritt zum Labeling der Videos ist die Erkennung von Objekten innerhalb der einzelnen Bilder, in diesem Fall von Fahrzeugen (u.a. Autos, Busse und Motorräder). Zur Objekterkennung wurde in dieser Arbeit das YOLOv4 Framework in der DarkNet Implementierung genutzt, das in Python eine einfach Schnittstelle zur Verfügung stellt und verhältnismäßig schnell läuft im Vergleich zu anderen Frameworks. [Anm.: Die Architektur von YOLOv4 ist im folgenden Wiki-Beitrag erläutert]. Eine weitere Variante der Objekterkennung ist das sogenannte Frame Differencing, bei dem die Veränderung zwischen zwei aufeinanderfolgenden Frames betrachtet wird. Über Erosion, Dilatation sowie Konturerkennung können daraus ebenfalls Bounding Boxes abgeleitet werden. Die Abbildung zeigt einen Vergleich von YOLO und Frame Differencing. Es ist ersichtlich, dass die Erkennung von YOLO wesentlich präsizer erfolgt. Ein weiterer Vorteil von YOLO liegt darin, dass nach den Klassen der Objekte gefiltert und damit etwa Radfahrende ignoriert werden können. Diese Option steht beim Frame Differencing nicht zur Verfügung, da die Art der Objekte nicht ermittelt wird. Insgesamt bietet YOLO damit mehr Möglichkeiten bei höherer Genauigkeit. Die erhöhte Verarbeitungsdauer spielt jedoch keine Rolle, da diese nicht in Echtzeit stattfinden muss und somit der zeitliche Aufwand keine Bedeutung hat.

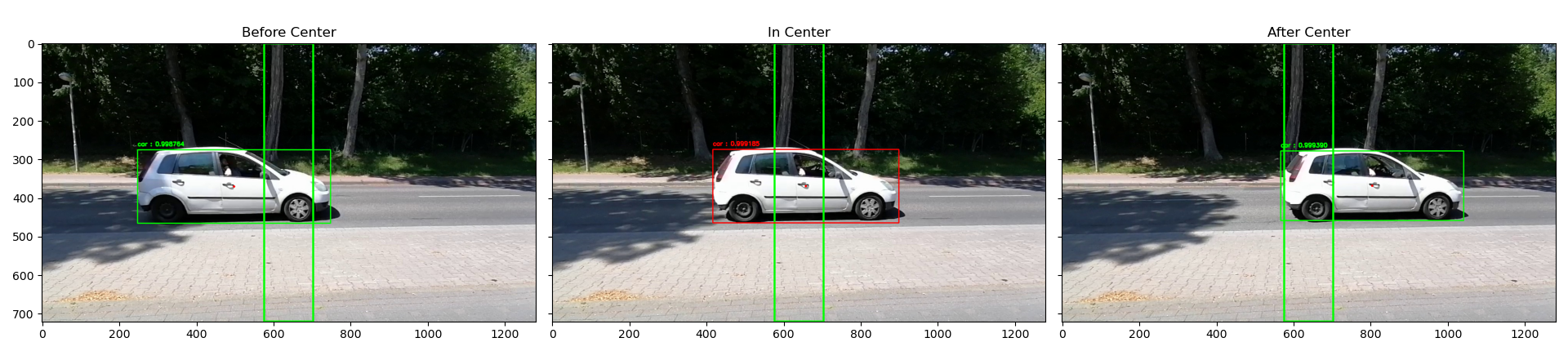
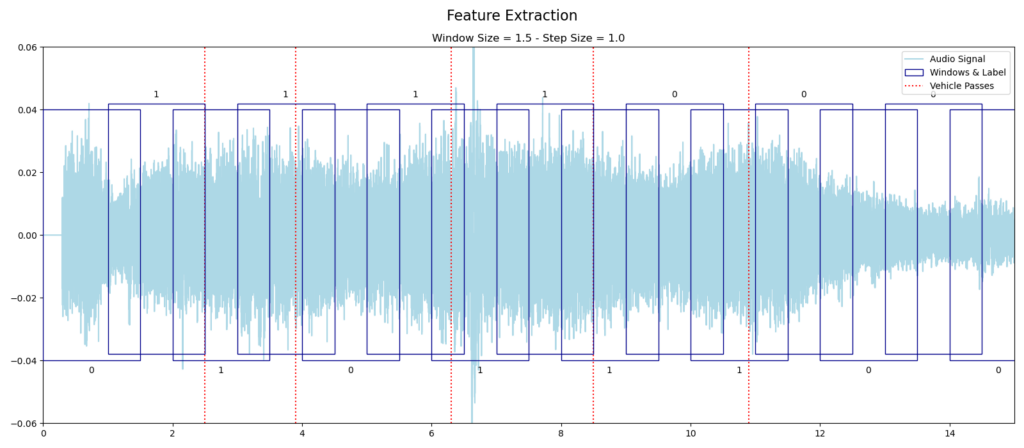
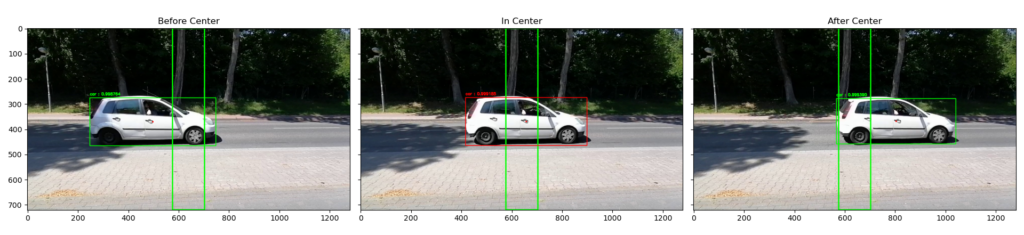
Im zweiten Teil der Videoverarbeitung geht es darum, die erkannten Objekte von YOLO weiter zu verarbeiten und die Zeitpunkte zu ermitteln, wann ein Fahrzeug die Aufnahme passiert hat. Die Abbildung zeigt beispielhaft die verwendete Vorgehensweise beim Labeling. Für die Bounding Boxes der erkannten Objekte wird der Mittelpunkt berechnet, der sogenannte Centroid. Das zweite wesentliche Element ist eine Box in der Mitte des Bildes, nachfolgend als Center Box bezeichnet. Für jeden Frame, also jedes einzelne Bild, wird überprüft, ob sich der Centroid eines Objekts innerhalb der Center Box befindet (in der Abbildung durch die farblich veränderte Bounding Box dargestellt). Sobald der Centroid eines Fahrzeugs die Center Box wieder verlässt, hat es die Mitte des Bildes wieder verlassen und gilt damit als vorbeigefahren. Zu dem entsprechenden Zeitpunkt, der auf Basis der Frames bestimmt wird, kann dann ein Label gesetzt werden.
Ein Problem der gewählten Labeling Methodik liegt darin, dass Fahrzeuge auf der hinteren Spur verdeckt werden können. YOLO ist dann nicht in der Lage, das hintere Fahrzeug zu erkennen und dementsprechend gibt es für den Moment auch keine Bounding Box mit Centroid. Im ungünstigsten Fall passieren zwei Fahrzeuge zum exakt gleichen Zeitpunkt die Mitte des Bildes und somit wird nur das eine als vorbeigefahren wahrgenommen. Bei der Auswertung der Videos hat sich gezeigt, dass dieser Fall nur sehr selten auftritt und kaum Fahrzeuge nicht gelabelt werden. Einen Ansatz zur Lösung dieses Problems könnte Objekt-Tracking bieten, das sich mit der Erkennung von gleichen Objekten in aufeinander folgenden Frames befasst. Die Methodik der Center Box müsste dann entsprechend angepasst werden, um alle Fahrzeuge zu erfassen. Damit einhergehend ergeben sich durch Ungenauigkeiten im Tracking weitere Probleme, die in Summe zu einer ähnlichen Fehlerquote beim Labeling führen könnten wie der gewählte Labeling-Prozess auf Basis der Center-Box.