
Value Imputation ist ein wichtiger Schritt im Preprocessing und befasst sich mit dem Füllen fehlender Werte – daher wird er meist im Anschluss an die Outlier Detection durchgeführt. Fehlende Werte sind ein großes Problem, wenn es um das Training von Machine Learning Modellen geht, und müssen daher entsprechend behandelt werden. Eine simple Variante besteht darin, alle Einträge mit fehlenden Werten aus dem Datensatz zu entfernen. Je nachdem, wie viele Elemente dabei entfernt werden, wird die Größe des Datensatzes deutlich reduziert und eventuell zu gering, damit ein Machine Learning Modell erfolgreich allgemeine Regeln ableiten kann. Die zweite Variante besteht darin, fehlende Werte zu füllen – die sogenannte Value Imputation. Dieser Artikel stellt verschiedene Varianten vor, wie fehlende Werte in Datensätzen gefüllt werden können.
Mean / Median / Mode – Impute #
Eine sehr simple Variante besteht darin, fehlende Werte eines Attributs auf Basis der verbleibenden Werte des Attributs zu füllen. Für numerische Werte können entweder Mittelwert oder Median verwendet werden, für kategorische Attribute wird meist der Modus (häufigster Attributwert) verwendet. Diese Variante der Value Imputation ist sehr simpel und erfordert auch bei großen Datensätzen keine große Rechenleistung. Jedoch sind die Ergebnisse meist eher mittelmäßig, da alle fehlende Werte unabhängig von weiteren Attributen mit den gleichen Werten gefüllt werden. Bei Klassifikations-Problemen gibt es die Variante, den Mittelwert aller Einträge mit der gleichen Klasse zu verwenden bei fehlenden Werten, um spezifische Informationen zu bekommen. Der folgende Codeblock zeigt, wie mit Pandas fehlende Werte mit dem Mittelwert gefüllt werden können.
# Fehlende Werte mit dem allgemeinen Mittelwert der Spalte füllen (Pandas)
data.fillna(value=data.mean())
# Fehlende Werte eines einzelnen Attributs mit dem spezifischen Mittelwert der Klasse füllen
col = 'Attributname'
# Mittelwert für je Klasse berechnen
mean_klassen = data.groupby('Label')[col].mean()
# Für jede einzelne Klasse...
for c in data['Label'].unique():
# ... ersetze fehlende Werte dieser Klasse mit dem Mittelwert
data.loc[(data['Label']==c) & (data[col].isna()), [col]] = mean_klassen[c]
Interpolation (nur bei Zeitreihen) #
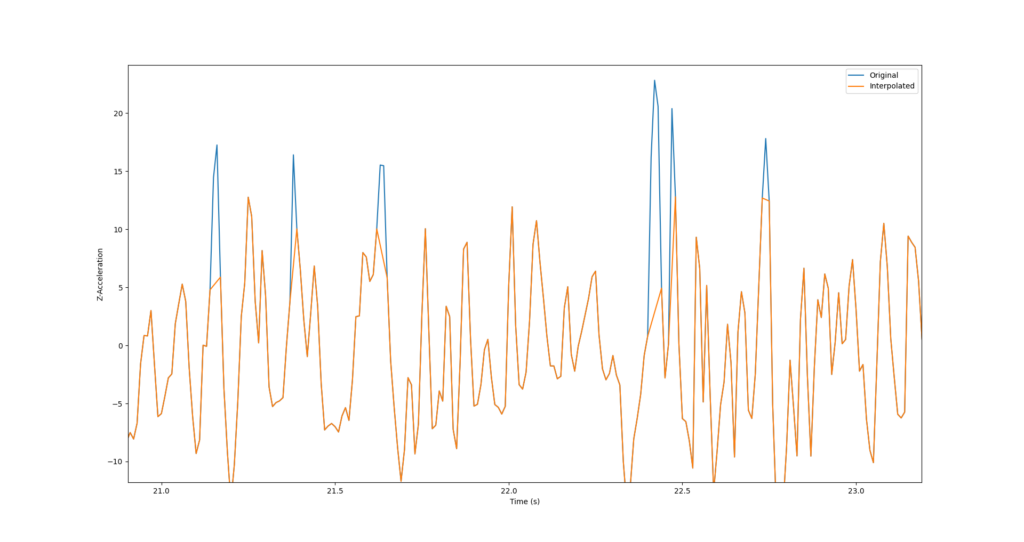
Die folgende Variante kann nur auf Daten angewandt werden, die im zeitlichen Zusammenhang zueinander stehen – den sogenannten Zeitreihen. Wird ein Datenpunkt als Ausreißer erkannt und entfernt oder liegt nicht vor, kann er auf Basis der zeitlich angrenzenden Datenpunkte berechnet bzw. interpoliert werden. Wenn also der Datenpunkt zum Zeitpunkt t keinen Wert hat, berechnet sich der Wert wie folgt.
y(t) = (y(t-1) + y(t+1)) / 2
Der Datenpunkt bekommt also den Mittelwert aus den beiden angrenzenden Messpunkten. Falls auch der direkte Nachbar keinen Wert hat, wird automatisch der nächste Datenpunkt mit einem Wert gewählt. Das Verfahren kann also keine Werte am Ende einer Zeitreihe auffüllen, da nur vorher ein Datenpunkt mit Wert bekannt ist. Die Abbildung zeigt beispielhaft, wie Datenpunkte durch Outlier Detection und Interpolation verändert werden.
KNN-Impute #
Die bisher vorgestellten Verfahren orientierten sich wenig bis gar nicht an den weiteren Verfügbaren Informationen aus weiteren Attributen. Beim KNN-Impute oder auch Bag-Impute wird auf Basis der Datenpunkte mit vorhandenen Werten bei einem Attribut ein KNN-Modell gebildet, dass dann auf Basis der weiteren Attribute eines Datenpunktes das fehlende Attribut vorhersagt. Die Logik dahinter liegt darin, dass Datenpunkte mit ähnlichen Werten unter den weiteren Attributen auch bei dem Attribut, wo fehlende Werte vorliegen, nah beieinander liegen bzw. ähnliche Werte aufweisen.
Weiterführende Links:
Imputation of missing values: https://scikit-learn.org/stable/modules/impute.html
A Guide To KNN Imputation: https://medium.com/@kyawsawhtoon/a-guide-to-knn-imputation-95e2dc496e



