
Unüberwachtes Lernen ist ein der Teilgebiete des maschinellen Lernens und kann verwendet werden, um aus vorliegenden Daten Gruppen zu identifizieren und Muster in den Daten zu erkennen. Im Gegensatz zum überwachten Lernen liegen dabei ausschließlich die Feature als Daten vor, nicht jedoch die zugehörigen Outputs bzw. Ergebnisse. Die Aufgabe von Algorithmen liegt im unüberwachten Lernen darin, diesen Output zu generieren.

Die wichtigsten Arten des unüberwachten Lernens sind:
- Clustering
Gruppierung von Datenpunkten zu Gruppen bzw. Clustern - Assoziationen
Suche nach Regeln, die Korrelationen zwischen den Datenpunkten beschreiben - Dimensionsreduktion
Extraktion relevanter Feature aus den Daten und Informationsverdichtung
Je nach vorliegenden Daten ergibt sich, welche der einzelnen Herangehensweisen bzw. Methoden des unüberwachten Lernens gewählt wird. Mögliche Anwendungen der verschiedenen Herangehensweise sind unter anderem:
Anwendungsbeispiele #
| Herangehensweise | Anwendung |
|---|---|
| Clustering | Kundensegmentierung, sprich das Gruppieren von Kunden nach ihren Kaufinteressen. |
| Assoziationen | Warenkorbanalyse – wenn ein Kunde Produkt X kauft, wird er auch Produkt Y oder weitere ähnliche Produkte kaufen (Standardbeispiel Windeln & Bier). |
| Dimensionsreduktion | Redundanzen aus den Daten entfernen und wirklich nur die relevanten Informationen extrahieren. |
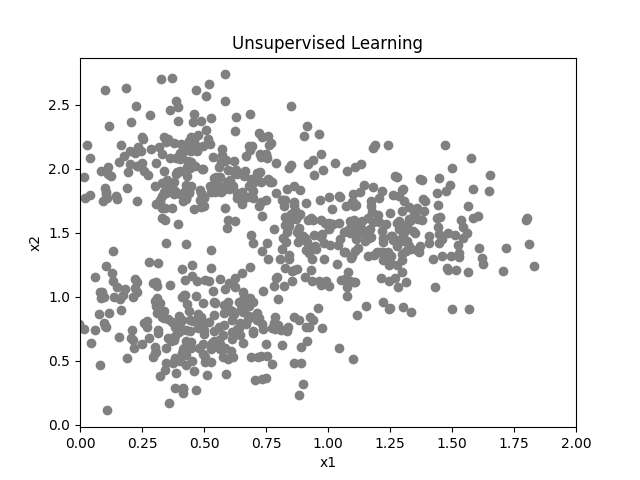
Die Abbildung soll dazu dienen, die Vorgehensweise bei der Verwendung des unüberwachten Lernens zu verdeutlichen.
Es liegen Datenpunkte ohne bekannte Klasse mit den Attributen x1 und x2 vor, die in der Abbildung als Scatter-Plot dargestellt werden. Über unüberwachtes Lernen sollen Muster bzw. mögliche Klassen in den Daten festgemacht werden. In diesem Fall wäre Clustering eine gute Wahl, um die Datenpunkte in Gruppen zu ordnen. Generell ist die Anzahl der Cluster meist nicht klar, in diesem Fall kann anhand der Visualisierung relativ schnell eine Anzahl von drei Clustern festgesetzt werden. Ein entsprechender Algorithmus (z.B. K-Means) teilt die Daten in Cluster ein, die für weitere Schritt verwendet werden können.
Weiterführende Links:
What is Unsupervised Learning?: https://www.ibm.com/cloud/learn/unsupervised-learning
Definition, Arten, Beispiele: https://datasolut.com/wiki/unsupervised-learning/



