
In der Trainingsphase geht es darum, ein Modell so zu trainieren, dass es möglichst gute Ergebnisse erzielt. Es soll also neue, unbekannte Daten möglichst gut klassifizieren bzw. vorhersagen können. Um das zu erreichen, nutzen wir bestimmtes Learning Setup.
Die Idee dahinter ist die Folgende: wenn wir ein Modell trainieren, dass alle unsere Daten zu 100% korrekt klassifizieren/vorhersagen kann, dann ist das zwar schön, aber was ist mit unbekannten Daten? Was ist, wenn wir unser Modell in der Praxis einsetzen wollen, um neue Datensätze klassifizieren/vorhersagen zu können? Möglicherweise kann unser Modell mit diesen neuen Daten nicht so gut umgehen.
Hierfür gibt es eine Lösung: das Aufteilen des ursprünglichen Datensatzes in drei kleine Datensätze: einen Trainingsdatensatz, einen Validation-Datensatz und einen Testdatensatz.
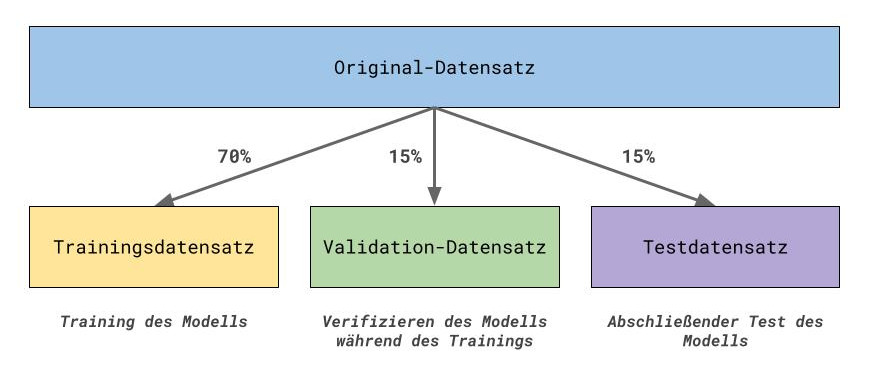
Der Trainingsdatensatz dient dazu, dass Modell zu trainieren. Während wir das Modell trainieren, nutzen wir den Validation-Datensatz als Abgleich, um zu überprüfen, dass das Modell auch auf unbekannten gut performt. Mit den Testdaten führen wir dann einen abschließenden Test des Modells durch. Daran können wir feststellen, wie “gut” das Modell ist, also wie gut es unbekannte oder neue Daten klassifizieren/vorhersagen kann.
Die prozentuale Aufteilung erfolgt nach einem sehr verbreiteten Schema. Vom Original-Datensatz werden 70% der Daten für das Training des Modells verwendet. Die restlichen 30% werden auf Validation- und Testdatensatz aufgeteilt. Die Prozentwerte sind jedoch nicht fest und je nach Daten und Datenmenge könnte man beispielsweise auch eine 80-20 bzw. 80-10-10-Aufteilung der Daten in Betracht ziehen.
Overfitting & Underfitting #
Ein paar Anmerkungen:
- Man verwendet nicht immer zwingend auch ein Validation-Datensatz. In einigen Anwendungen wird das Modell auch ausschließlich mit dem Trainingsdatensatz trainiert. Ein anderer Ansatz ist die Cross-Validation (kurz CV), bei der die Validation-Daten bei jeder Trainings-Runde aus den Trainingsdaten zufällig ausgewählt werden. Damit bleiben dann mehr Testdaten übrig (z. B. die vollen 30%).
- Im Idealfall werden die Daten so aufgeteilt, dass in jedem der zwei oder drei Datensätze die Proportionen der Klassen annähernd mit dem denen des Original-Datensatzes übereinstimmen. Dieser Ansatz wird auch stratified splitting genannt.
Es wäre für die Performance des Modells auch äußerst abträglich, wenn es nur mit Datensätzen der Klasse A gelernt wird, und dann Testdaten klassifizieren soll, die ausschließlich Klasse B enthalten.
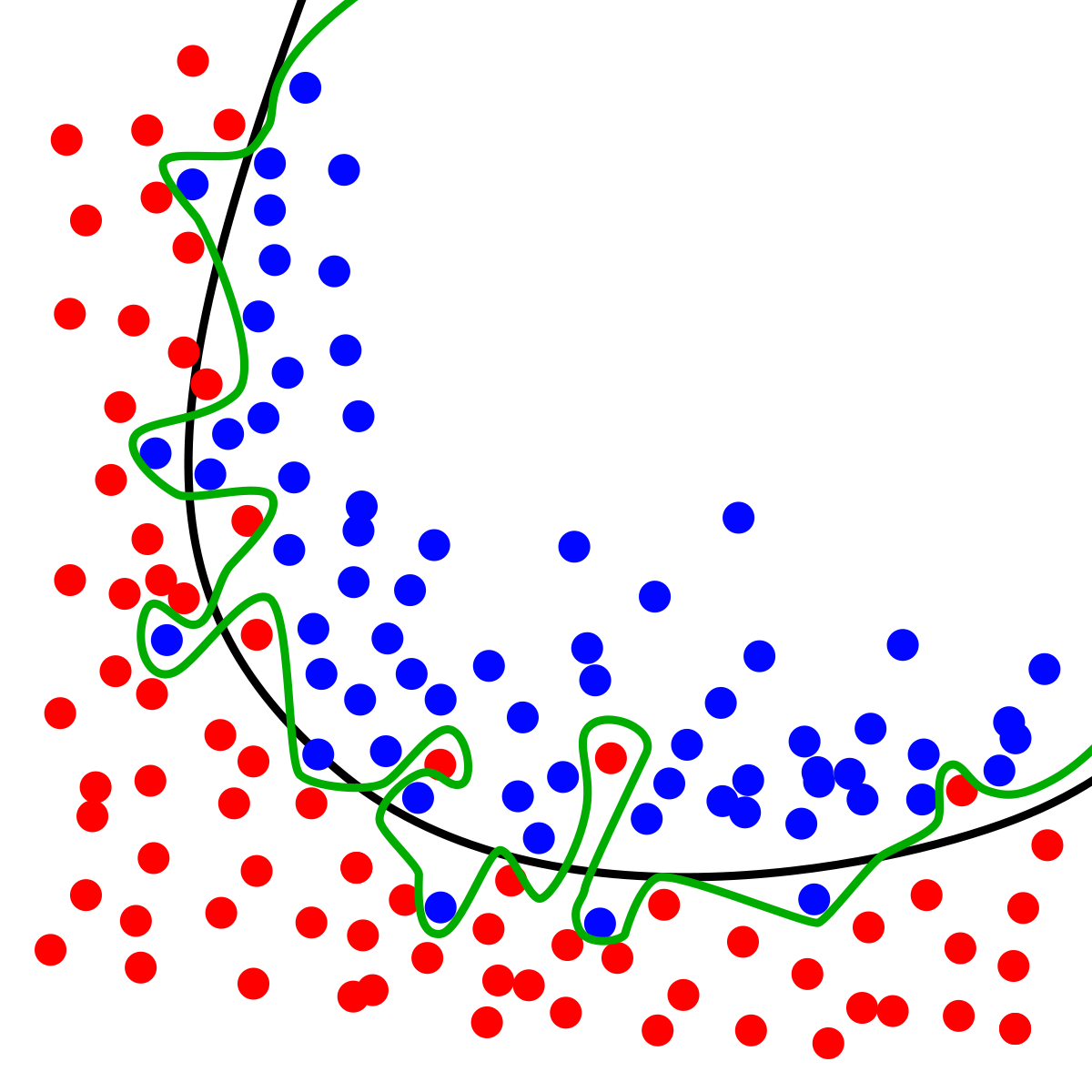
Aber wieso genau teilen wir unsere Daten denn jetzt so auf? Damit unser Modell nicht overfitted, sich also nicht zu sehr auf die Trainingsdaten einstellt. Abbildung 2 stellt mit der grünen Linie als Decision Boundary sehr anschaulich dar, was bei Überanpassung des Modells auf die Trainingsdaten passieren kann. Eine bessere Klassifizierung erhalten wir, wenn wir die schwarze Linie als Decision Boundary nutzen, die wesentlich allgemeiner klassifiziert, als die grüne.




{kind=link}