
Sampling ist ein Verfahren aus der Phase der Modelloptimierung und wird sehr häufig bei ungleichen Klassenverteilungen eingesetzt. Wenn die Klassen im Datensatz zu einer Problemstellung extrem ungleich verteilt sind, entsteht dabei beim Trainieren der Modelle ein sogenannter Bias in Bezug auf die Klasse, von der mehr Samples vorhanden sind. Dies bedeutet, dass bei der Vorhersage von neuen Datenpunkten diese Klasse deutlich häufiger vorhergesagt wird. Ein klassisches Beispiel sind Datensätze zur Betrugserkennung, bei denen meist nur unter 5% der Daten wirklich Betrug sind. Entsprechend könnte ein Modell eine Accuracy von 95% erzielen, indem alle Daten als kein Betrug vorhergesagt werden – dies ist natürlich nicht wünschenswert, daher kann durch Sampling das Verhältnis zwischen Betrug und kein Betrug aneinander angeglichen werden. Zudem sollte bei Datensätzen mit unausgeglichenen Klassenverhältnissen eher der F1-Score als Metrik verwendet werden und nicht die Accuracy. Die beiden folgenden Abbildungen stehen für ein binäres Klassifikationsproblem (z.B. Betrugserkennung) und bilden die Basis für die vorgestellten Sampling Verfahren.
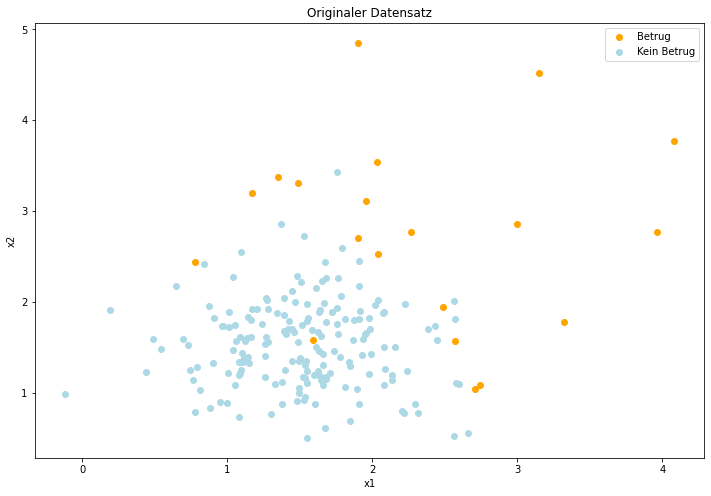
Betrug und Kein Betrug
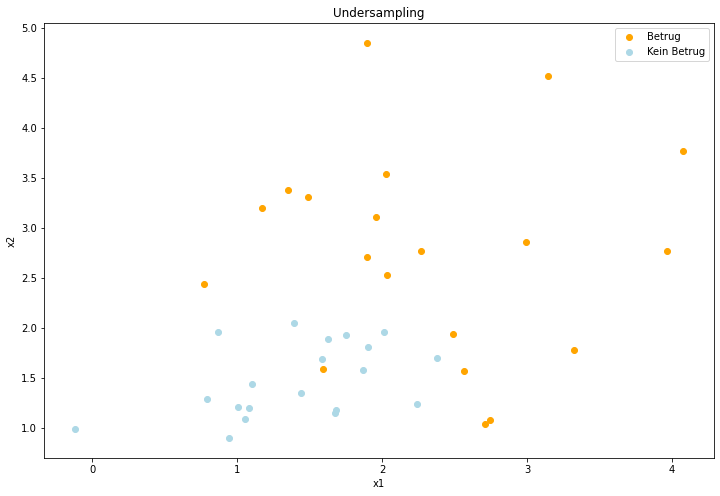
Undersampling #
Beim Undersampling werden die Verhältnisse der Klassen aneinander angeglichen, indem zufällig Sample der Majority-Class (=Klasse mit mehr Datenpunkten) aus dem Datensatz entfernt werden, bis die Verhältnisse aneinander angeglichen sind. Eine Implementierung des Verfahrens wird mit dem RandomUnderSampler aus dem Paket Imblearn zur Verfügung gestellt, das automatisch mit Scikit-Learn installiert wird. Die Abbildung zeigt gut, wie Datenpunkte der Majority-Class entfernt wurden und nachfolgend für beide Klassen gleich viele Datenpunkte vorhanden sind.
Oversampling #
Das Oversampling verfolgt genau den umgekehrten Ansatz zum Undersampling und dupliziert solange Samples der Minority-Class (=Klasse mit weniger Datenpunkten), bis die Verhältnisse aneinander angeglichen sind. Da es sich um Duplikate handelt, ist der Effekt bei der Visualisierung nicht wirklich bis gar nicht zu sehen und die Abbildung sieht genauso aus wie der originale Datensatz. Oversampling kann schnell dazu führen, dass je nach Lernverfahren einzelne Koordinaten bzw. Kombinationen aus Attributen auswendig gelernt werden, da diese eine relativ große Anzahl an Datenpunkten einer Klasse widerspiegeln.
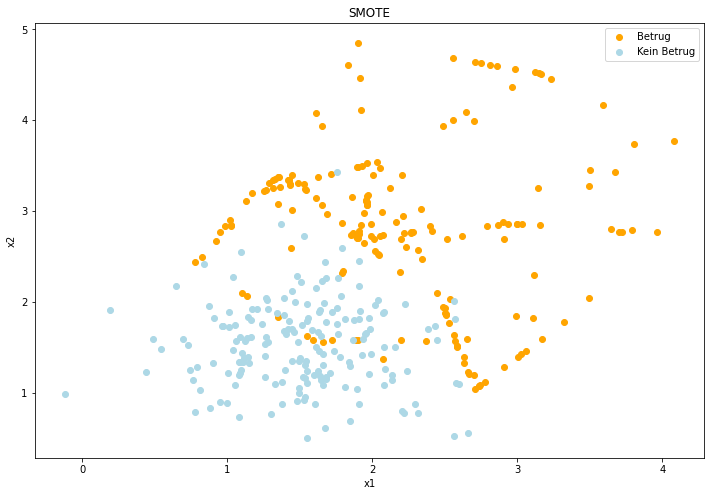
SMOTE #
SMOTE ist ebenfalls ein Oversampling Verfahren und steht dabei genauer gesagt für Synthetic Minority Over-sampling Technique. Im Gegensatz zum RandomOverSampling werden jedoch nicht nur bestehende Datenpunkte dupliziert, sondern synthetisch neue Datenpunkte der Minority-Class generiert. Dahinter liegt die Annahme, dass Punkte einer Klasse nah beieinander und in festen Bereichen liegen. SMOTE generiert also neue Punkte, die zwischen den bereits bestehenden Punkten der Klasse liegen und vergrößert damit mehr oder weniger den Bereich der Klasse. Das Vorgehen ist in der Abbildung gut zu sehen, wie die neuen Datenpunkte in bestimmten Bereichen und auf Linien zwischen bestehenden Punkten der Minority-Class liegen.
Weiterführende Links:
SMOTE (Paper): https://arxiv.org/pdf/1106.1813.pdf
Sapling Techniques: https://towardsdatascience.com/sampling-techniques-a4e34111d808
Imbalanced Learn Documentation: https://imbalanced-learn.org/stable/



