
Perceptron Learning Algorithm, kurz PLA, bezeichnet ein sehr simples Lernverfahren zur Modellierung von binären Klassifikations Problemen. Die sogenannte Decision Boundary, also die Grenze zwischen den beiden Klassen, ist dabei im im zweidimensionalen Raum eine Line bzw. allgemein gesagt eine n-1 dimensionale Hyperebene, wobei n die Anzahl der Input Feature beschreibt. Daher ist das Perceptron nur im Falle von linear trennbaren Daten in der Lage, die Klassifikation ohne Fehler vorzunehmen, da andersfalls ohne weitere Transformation der Daten keine passende Hyperebene gefunden werden kann. Dieser Wiki Artikel erklärt grundlegend die Mathematik hinter dem PLA, verdeutlicht den Algorithmus zur Bestimmung der Gewichte und visualisert an einem praktischen Beispiel die Rolle der linearen Trennbarkeit der Daten.
Mathematische Grundlage #
Die Grundidee des Perceptrons besteht darin, die Input Feature einzeln zu gewichten und anschließend die Summe zu bilden – daher spricht man auch von einer gewichteten Summe. Falls diese Summe einen bestimmten Grenzwert überschreitet wird der Datenpunkt bzw. die Kombination an Input Features als +1-Klasse klassifiziert, andernfalls als -1-Klasse. Die gezeigte Formel beschreibt genau diesen Sachverhalt mathematisch.
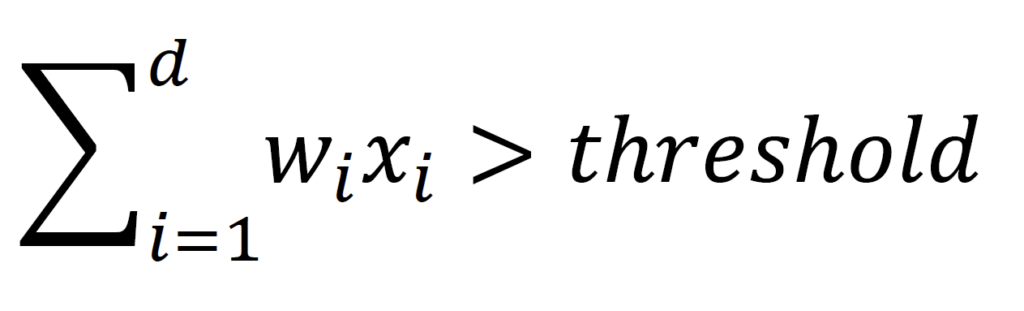
Der Grenzwert (in der Formel als Threshold bezeichnet), oder auch Biaswert, kann im nächsten Schritt in die gewichtete Summe integriert werden. Dafür wird dem Feature-Vektor x eine 1 vorangestellt wird, d.h. x0=1. Im Folgenden wird im Summenzeichen ab dem Index i=0 gestartet, um den Biaswert mit in die gewichtete Summe aufzunehmen. Daraus ergibt sich die folgende Formel, wobei die gewichtete Summe gleichermaßen als Dot-Product zwischen Feature Vektor und Weight Vektor ausgedrückt werden kann.
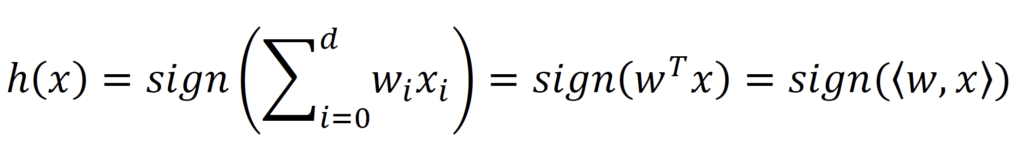
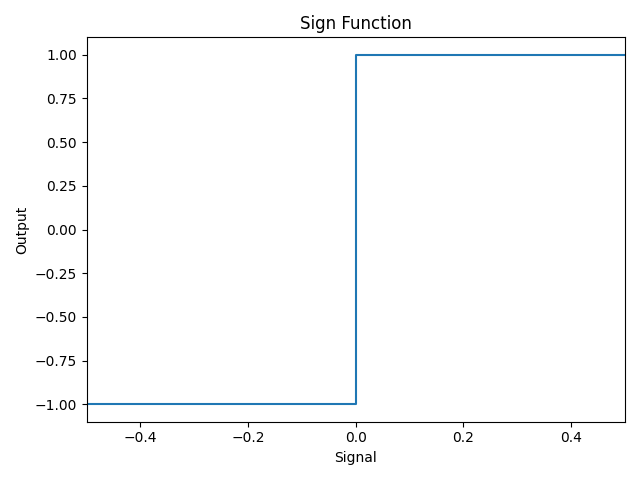
Die Sign-Funktion ist dabei eine Stufenfunktion, d.h. alle Inputs unterhalb von 0 werden als -1 ausgegeben, alle Input größer oder gleich 0 als +1 – also der entsprechenden Klassen-Zuweisung aus der ersten Formel. Je nach Gewichten ergibt sich eine Decision Boundary, also die Grenze zwischen den beiden Klassen. So eine Grenze ist beispielhaft in der Abbildung dargestellt im zweidimensionalen Feature Space.
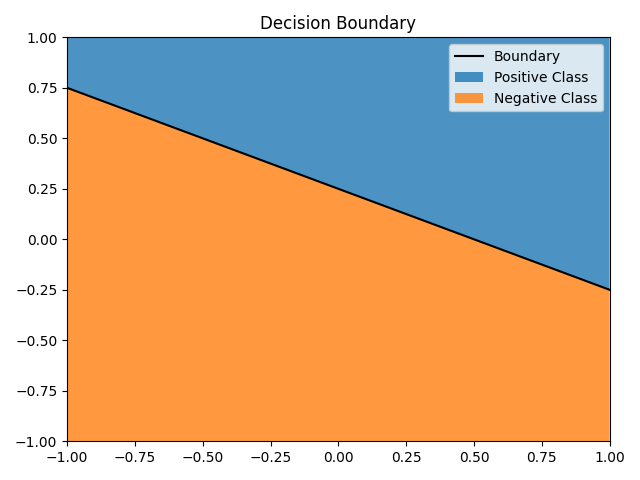
Optimierung der Gewichte #
Nachdem die grundlegende Funktionsweise des Perceptron erklärt wurde stellt sich die Frage, wie die optimalen Gewichte w gefunden werden können. Dazu kommt der eigentliche Perceptron Learning Algorithmus ins Spiel, der das eigentliche “Training” des Perceptrons beschreibt.
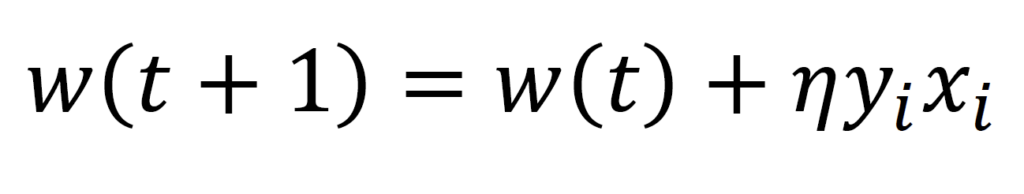
fehlerhaft klassifizierten Datenpunktes.
- Initialisiere alle Gewichte mit dem Wert 0.
- Finde einen fehlerhaft klassifizierten Datenpunkt, bei dem die tatsächliche Klasse nicht mit dem Output der Sign-Funktion übereinstimmt.
- Aktualisiere die Gewichte nach der rechtsstehenden Formel, wobei die Lernrate 𝜂 die Größe der Anpassung kontrolliert.
- Wiederhole Punkt 3 und 4 solange, bis alle Datenpunkte korrekt klassifiziert werden.
- Gebe die finalen Gewichte zurück.
Eine Variante des Lernverfahrens ist der sogenannte Pocket-Algorithmus, bei dem die bisher optimalen Gewichte mit der geringsten Fehlerrate gespeichert und am Ende zurückgegeben werden. Die oben aufgeführten Schritte werden durch eine maximale Zahl an Gewichtsänderungen begrenzt, wodurch möglicherweise kein Optimum erreicht wird.
Rolle der linearen Trennbarkeit #
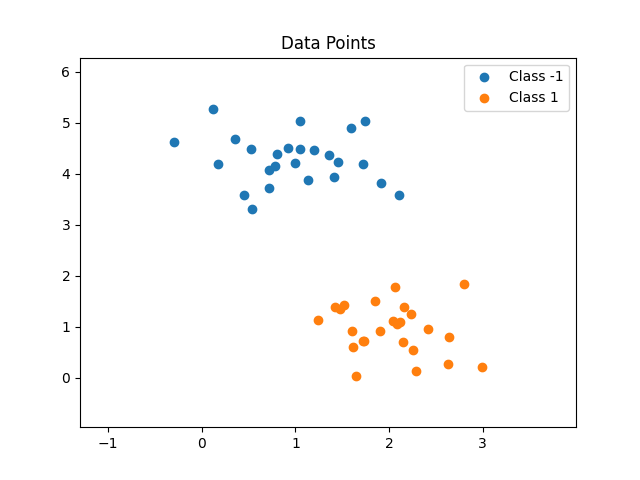
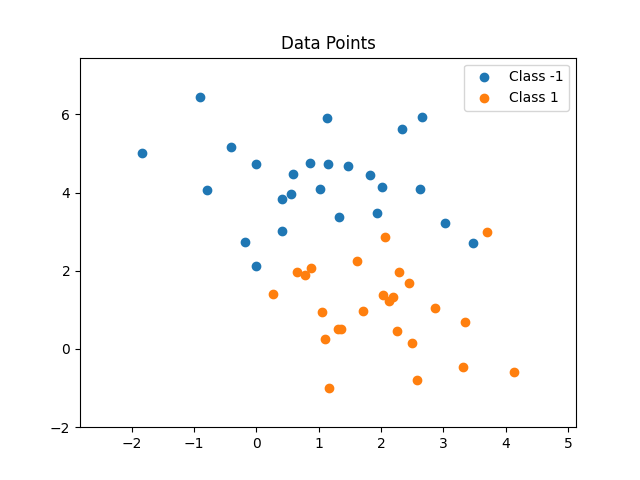
Wie bereits genannt ist die Decision Boundary immer linear. Das heißt im zweidimensionalen Raum eine Linie, ganz allgemein gesprochen eine d-1-dimensionale Hyberebene. Für den Fall, dass die Datenpunkte linear trennbar sind, können immer optimale Gewichte gefunden werden (die maximale Anzahl der Fehler wird dabei durch das Novikoff Theorem limitiert). Falls die Datenpunkte jedoch nicht linear trennbar sind, wird der Algorithmus kein Optimum finden. Durch die Anpassung der Boundary in eine Richtung, um den aktuell gewählten Datenpunkt richtig zu klassifizieren, wird mindestens ein anderer Datenpunkt in Folge fehlerhaft klassifiziert. Daher sollte immer eine maximale Anzahl an Anpassungen festgelegt werden, um nicht in eine Endlosschleife zu gelangen. Als Ergebnis kommt daher keine fehlerfreie Klassifikation zu Stande.
Weiterführende Links #
GitHub Repository mit Python Code: https://github.com/NilsHMeier/Learning_from_Data
Novikoff Theorem: https://meticulousdatascience.com/assets/pdf/novikoff_theorem.pdf
A Graphical Explanation Of Why It Works: https://towardsdatascience.com/perceptron-learning-algorithm-d5db0deab975



