
Outlier Detection meint das Finden von sogenannten Ausreißern in den Daten, die für weitere Schritte unerwünscht sind und Machine Learning Ergebnisse maßgeblich beeinflussen können. Als Ausreißer werden allgemein Datenpunkte bezeichnet, die sich vom Großteil der restlichen Daten unterscheiden und Werte weit entfernt des Durchschnitts annehmen. Mithilfe einer Outlier Detection werden eben diese Datenpunkte erkannt und können anschließend entfernt werden. Beispiele für Ausreißer können zum Beispiel sein:
- Beschleunigungsdaten, die extrem hohe unrealistische Werte abbilden
- GPS-Koordinaten, die stark von der vorherigen Position abweichen
- Herzfrequenzwerte, die sehr starke Änderungen abbilden
Die beiden folgenden Abbildugen zeigen beispielhaft, welche Form Outlier in Daten haben können.
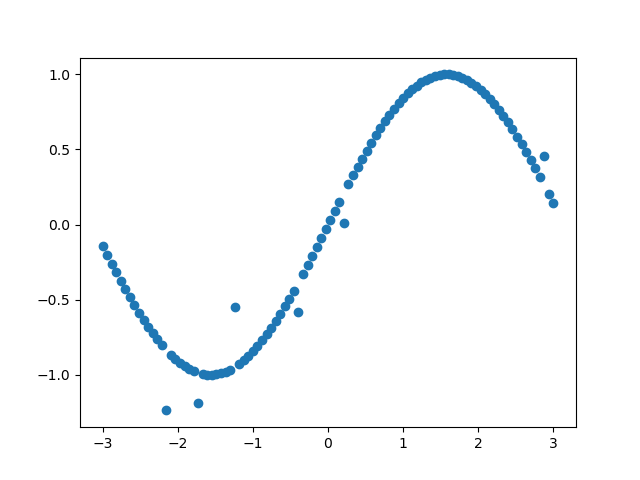
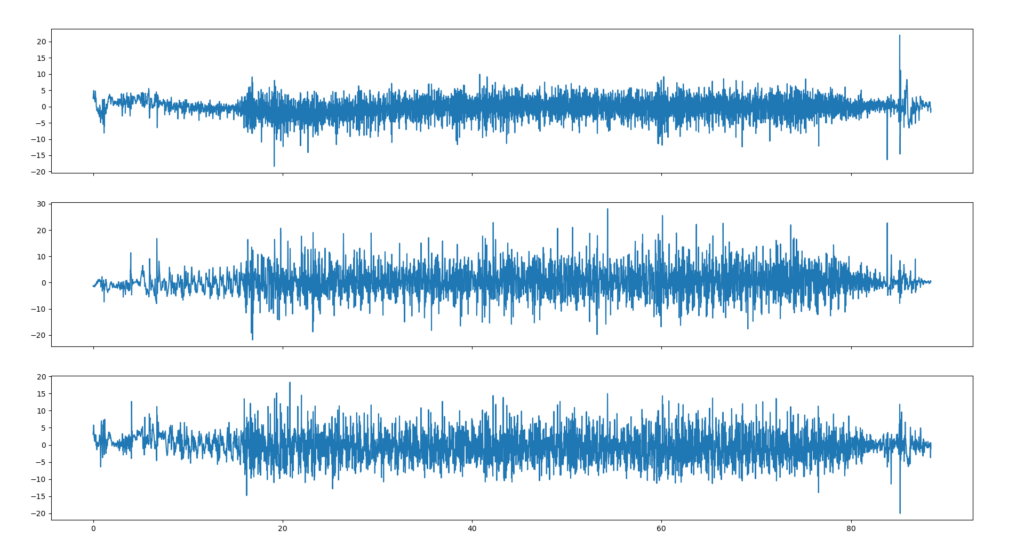
Gründe für Ausreißer in Datensätzen:
- Menschliche Fehler beim Erfassen (z.B. falsche Eingaben)
- Messfehler durch schlechte Genauigkeiten
- Fehler beim Data Processing (falsche Daten miteinander kombiniert)
In diesem Artikel werden zwei verschiedene grundlegende Varianten der Outlier Detection vorgestellt. Diese sind relativ allgemein einsetzbar, liefern jedoch nicht zwingend bei jedem Datensatz passende Ergebnisse. In einem weiteren Artikel werden Custom-Verfahren erklärt, die je nach Beschaffenheit der Daten zu besseren Ergebnissen führen können als die klassischen Verfahren.
Distribution Based Outlier Detection #
Bei der verteilung basierten Ausreißererkennung (engl. Distribution Based Outlier Detection) wird die Annahme getroffen, dass Daten einer Messung mit der Standardabweichung Sigma um den Mittelwert herum normalverteilt sind. Dadurch ergibt sich für jeden Datenpunkt der Aufnahme eine Wahrscheinlichkeit, dass er zu dieser Normalverteilung gehört. Über das sogenannte Chauvenet-Kriterium kann eine Untergrenze festgelegt werden, ab der ein Punkt als Ausreißer markiert bzw. behandelt wird.
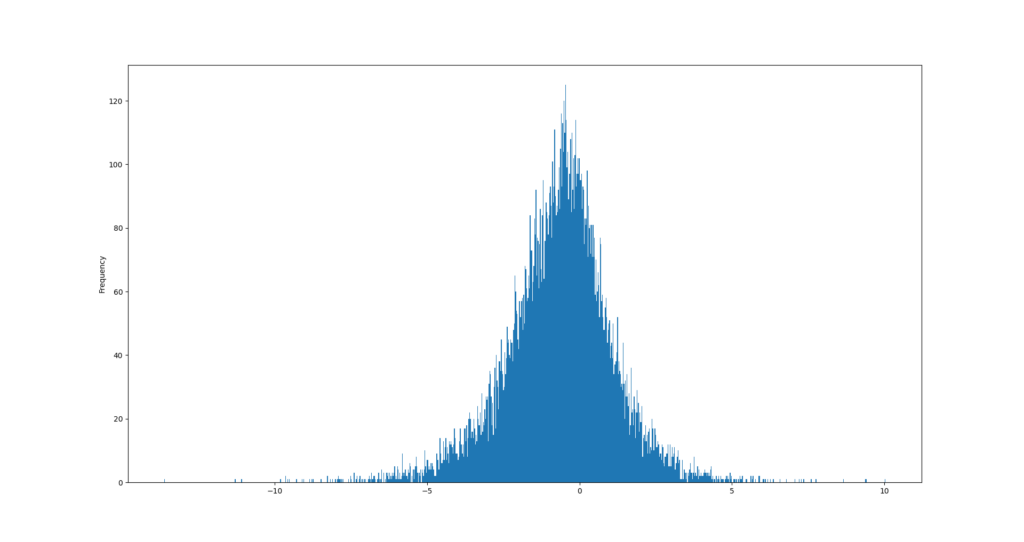
Wird das Chauvenet-Kriterium bspw. auf 0.5 gesetzt, werden alle Punkte als Ausreißer erkannt, die mit einer Wahrscheinlichkeit von unter 0.5% zur Normalverteilung der Daten gehören. Je nachdem, wie hoch das Kriterium angesetzt wird, ändert sich entsprechend die Anzahl der erkannten Ausreißer (dies wird in der Abbildung verdeutlicht). Wie hoch die optimale Grenze ist, also auf welchen Wert das Chauvenet-Kriterium gesetzt werden muss, hängt vom weiteren Ziel ab und wird häufig erst mit der Zeit ermittelt.

Distance Based Outlier Detection #
Neben den verteilungs basierten Verfahren können Outlier auch auf Basis von Distanz und Dichteverteilungen der Daten erkannt werden. Eins dieser Verfahren ist der Local Outlier Factor, kurz LOF. Die Idee hinter dem Algorithmus besteht darin, die Dichte rund um einen Punkt mit der Dichte um die nähesten k Nachbarn des Punktes zu vergleichen. Falls die Dichte deutlich geringer ist, liegt der Punkt nicht innerhalb eines Clusters von Datenpunkten und ist damit tendenziell ein Ausreißer. Sowohl die k-Nachbarn, die betrachtet werden sollen, als auch die Grenze, ab welchem Verhältnis ein Punkt als Ausreißer gilt, müssen manuell gesetzt werden und beeinflussen jeweils die Ergebnisse des Verfahrens.
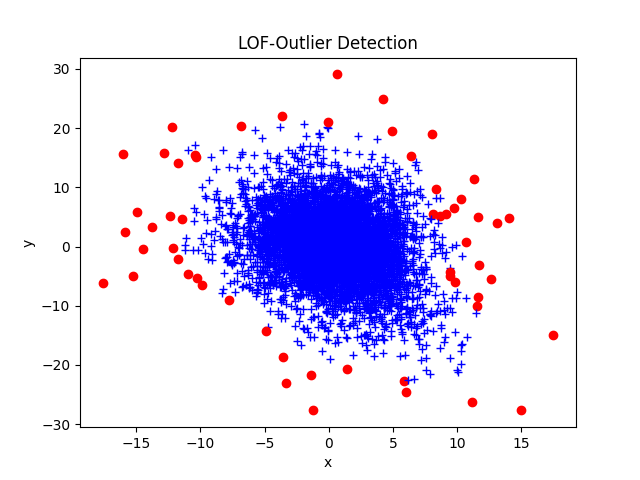
Weiterführende Links:
Outlier detection with Local Outlier Factor: https://scikit-learn.org/stable/auto_examples/neighbors/plot_lof_outlier_detection.html
A Brief Overview of Outlier Detection Techniques: https://towardsdatascience.com/a-brief-overview-of-outlier-detection-techniques-1e0b2c19e561



