
Logistische Regressionen sind ein Lernverfahren aus dem Bereich des überwachten Lernens und können sehr gut für binäre Klassifikations-Probleme eingesetzt werden. Dazu zählen zum Beispiel Modelle, die zur Betrugserkennung bei Zahlungsvorgängen oder Überweisungen eingesetzt werden. Dabei gibt es die Klassen Kunde betrügt und Kunde betrügt nicht – die logistische Regression gibt dabei jeweils eine Wahrscheinlichkeit aus, mit der ein Kunde betrügt und das Unternehmen kann eine individuelle Obergrenze festlegen, ab der ein Zahlungsvorgang händisch überprüft werden soll. Nachfolgend wird die Funktionsweise der logistischen Regression erläutert, wie die Inputs in Wahrscheinlichkeiten und sogenannte Logits umgewandelt werden.

Die obige Abbildung zeigt die logistische Funktion, die (wie es der Name erwarten lässt) die Basis für die Funktionsweise der Logistischen Regression. Die entsprechende Ausgabe der Funktion stellt die Wahrscheinlichkeit dar, dass ein Event eintreten wird – wie bspw. ein Betrug. Standardmäßig wird die Wahrscheinlichkeit direkt in sogennate Logits umgewandelt, bei denen 1 bedeutet Event tritt ein und 0 bedeutet Event tritt nicht ein – dabei wird 0.5 als Grenzwert der Umwandlung verwendet.
Rolle der Input-Feature #
Der Input für die logistische Funktion besteht dabei aus den verfügbaren Features – genauer gesagt der gewichteten Summe der einzelnen Feature. Das bedeutet, für jedes einzelne Feature ermittelt das Lernverfahren einen Koeffizienten, der in der gewichteten Summe entsprechend genutzt wird. Die Berechnung der gewichteten Summe x, die dann als Input für die logistische Funktion genutzt wird, sieht also wie folgt aus:
x = k0 + f1*k1 + … + fn*kn
k0 steht dabei für einen festen Wert (auch Bias genannt), der prinzipiell indirekt eine Verschiebung entlang der Schwelle von 0.5 bewirkt. Beim Training der logistischen Regression werden die einzelnen Koeffizienten sowie der Bias-Wert optimal angepasst, um auf den Trainingsdaten die bestmögliche Genauigkeit zu erzielen.
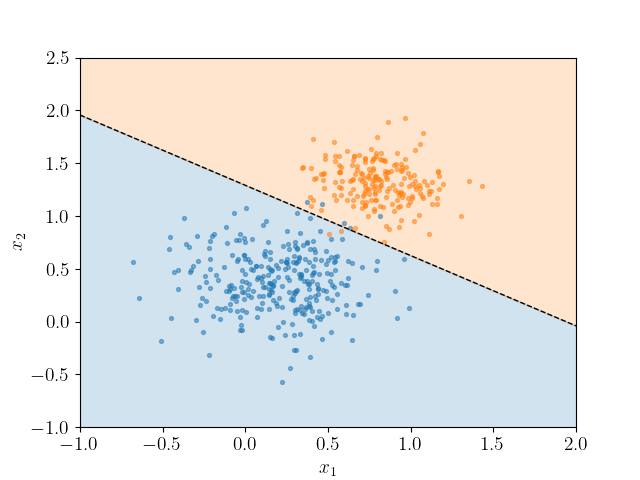
Die Abbildung verdeutlicht beispielhaft, wie durch eine logistische Regression eine Grenze zwischen zwei Klasse gezogen wird. Bei zwei Variablen, dementsprechend im zweidimensionalen Raum, ist die Abgrenzung eine Linie. Im dreidimensionalen Raum werden Klassen durch eine Ebene getrennt, die soganannte Hyperebene. Sobald mehr als drei Variablen Input der logistischen Regression sind, kann die Entscheidungsgrenze nicht mehr sinnvoll visualisert werden bzw. ist für Menschen nicht mehr vorstellbar.
Weiterführende Links:
Logistic Regression (sklearn): https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
Logistic Regression for Machine Learning: https://machinelearningmastery.com/logistic-regression-for-machine-learning/



