
K-Nearest Neighbours ist ein relativ simpler Machine Learning Algorithmus, der Daten aufgrund ihrer Ähnlichkeit in den Features klassifiziert bzw. bekannten Gruppen zuordnet. Er zählt daher zu den Methoden des überwachten Lernens und wird zudem dem sogenannten Lazy-Learning zugeordnet, da erst bei der Vorhersage neuer Beispiele etwas berechnet wird. Im Gegensatz dazu leiten z.B. Entscheidungsbäume die Entscheidungen, die zum Klassifizieren neuer Punkte nötig sind, bereits beim Training und nicht erst zur Laufzeit ab.
Ein Beispiel: Wir haben eine Vielzahl an Daten zu den Gewichten und Größen von Katzen und Löwen aufgenommen. Ein KNN-Algorithmus würde etwas Großes und Schweres auf Basis dieser Daten sehr wahrscheinlich den Löwen zuordnen, bereits ähnliche Größen und Gewichte aus der Gruppe „Löwen“ kennt.
Genau dies ist die Kernidee hinter dem KNN-Algorithmus: Er geht davon aus, dass ähnliche Dinge in unmittelbarer Nähe existieren. Mit anderen Worten: Ähnliche Dinge sind nahe beieinander. Die Grafik visualisiert ein paar Beispieldaten der Gewichte und Größen von Katzen und Löwen.

Funktionsweise des Verfahrens #
Wenn ein neuer Datenpunkt hinzugefügt, bei nur Größe und Gewicht bekannt sind, nicht aber die Klasse des Datenpunktes, geht der KNN-Algorithmus wie folgt vor:
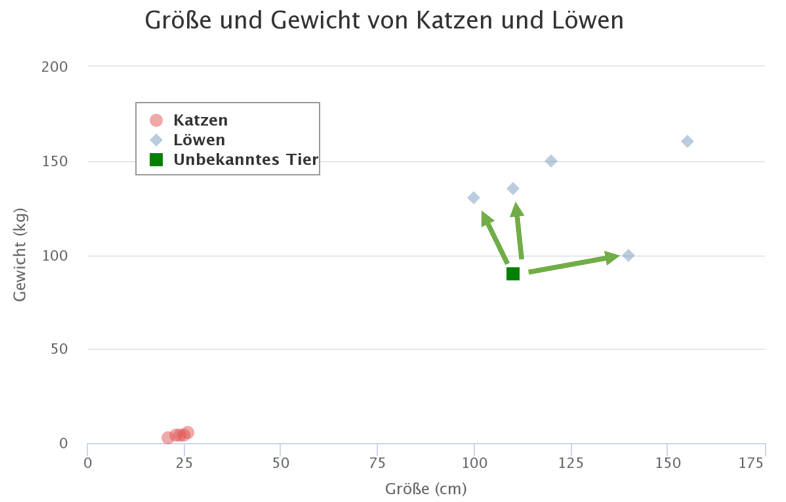
Er schaut sich die nächstgelegenen Datenpunkte an (= die „nearest neighbors“ oder „nächsten Nachbarn“). Das K in Knn definiert, anhand wievieler Datenpunkte in der Nähe ein unbekannter Datenpunkt klassifiert wird. Wenn K = 3 ist, schaut sich der Algorithmus entsprechend die 3 nächsten Datenpunkte im umliegenden Bereich an, um den unbekannten Datenpunkt zu klassifizieren. Die 3 nächstgelegenen Datenpunkte (basierend auf der minimalsten Distanz) sind in der Abbildung markiert. Die drei nächsten Datenpunkte entsprechen der Klasse „Löwe“ – daher wird das unbekannte Tier vom Knn-Algorithmus als Löwe klassifiziert.
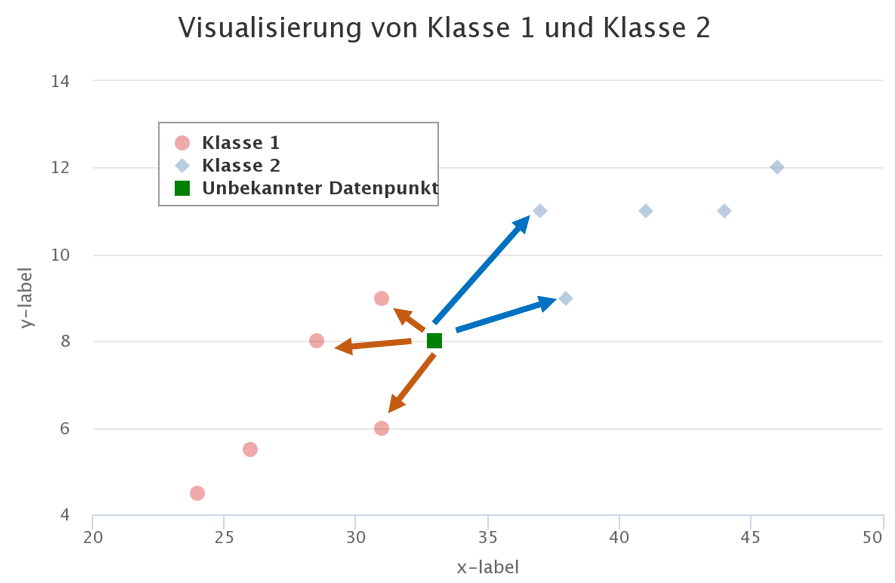
Das erste Beispiel ist relativ einfach gehalten. Es gibt natürlich auch Fälle, in denen ein unbekannter Datenpunkt in der Mitte zwischen zwei Klassen liegt. Bei einem solchen Fall wird dann abgewogen. Nehmen wir ein neues Beispiel mit den Klassen 1 und 2. Wir definieren K = 5, prüfen also anhand von 5 Nachbarn, wie unser unbekannter Datenpunkt eingeordnet werden soll. Unser unbekannter Datenpunkt hat die minimale Distanz zu drei Datenpunkten der Klasse 1 und zwei Datenpunkten der Klasse 2. Unser Algorithmus klassifiziert folglich den unbekannten Datenpunkt als Klasse 1.
Weiterführende Links:
K-Nearest-Neighbours: https://www.ki-business.de/blog/knn
KNeighborsClassifier (Sklearn): https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html



