
K-Means ist ein sehr simples und wohl das bekannteste Clustering-Verfahren und zählt dementsprechend zum Bereich des unüberwachten Lernens. Der K-Means Algorithmus bekommt also nur die Input Features ohne Klassen und weist jedem Datenpunkt ein Cluster zu. Unter dem Begriff Cluster versteht man ganz allgemein eine Gruppe von Datenpunkten, die räumlich nah beieinander liegen und somit gewisse Ähnlichkeiten aufweisen. Dem K-Means Algorithmus muss dabei als Parameter übergeben werden, wie viele Cluster aus den Daten gebildet werden sollen. Je nach Beschaffenheit der Daten ist nicht direkt ersichtlich, wie viele Cluster sinnvolle Ergebnisse liefern – daher wird mit verschiedenen Werten experimentiert, bis die Ergebnisse zufriendenstellend sind. Die nachfolgenden Abbildungen verdeutlichen beispielhaft die Funktionsweise von K-Means.
Die Grafiken wurden mit dem Tool erzeugt, das unter den weiterführenden Links zu finden ist.
Funktionsweise von K-Means #

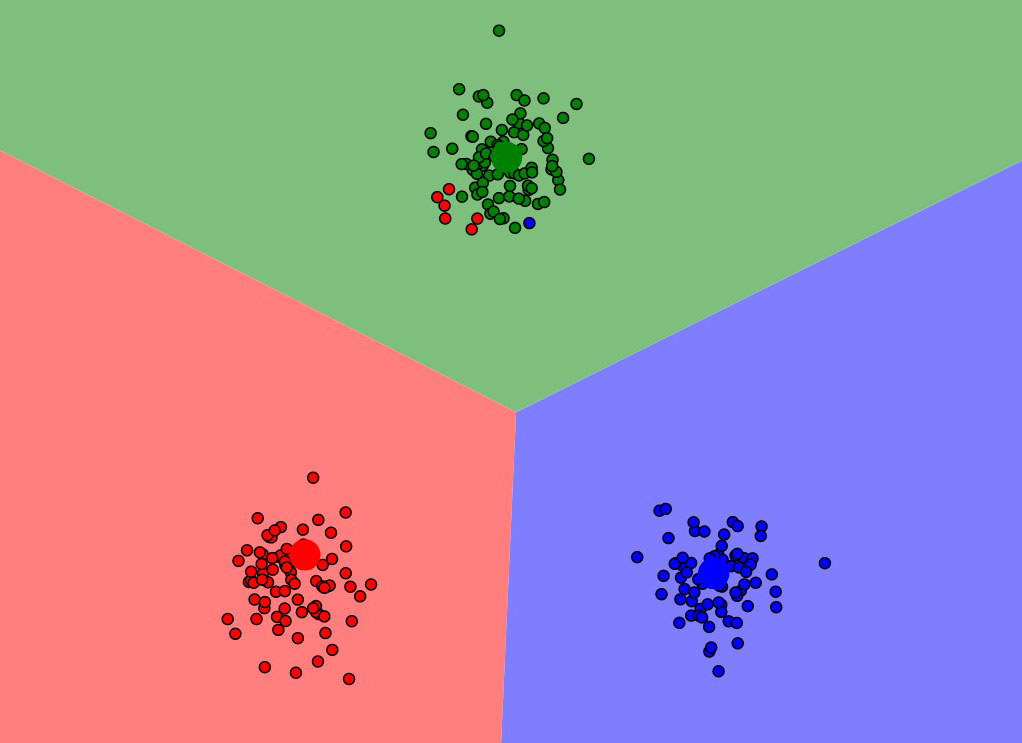


Die Cluster im gezeigten Beispiel sind natürlich extrem deutlich – daher funktioniert der K-Means Algorithmus auch sehr problemlos mit wenigen Iterationen. Bei komplexeren Daten werden häufig deutlich mehr Schritte benötigt, bis alle Centroids an den optimalen Positionen sind und dementsprechend keine Änderungen bzw. Neuzuweisungen auftreten. Experimentieren Sie mit dem Tool (s. weiterführende Links) einfach ein bisschen rum, wie sich Centroids bei verschiedenen Daten verhalten und wie das zufällige Initialisieren den Ablauf und die Ergebnisse beeinflusst.
Weitere Informationen #
Weiterführende Links:
Understanding K-Means Clustering: https://towardsdatascience.com/understanding-k-means-clustering-in-machine-learning-6a6e67336aa1
Visualizing K-Means Clustering: https://www.naftaliharris.com/blog/visualizing-k-means-clustering/



