
Hyperparameter Tuning meint die Optimierung der externen Parameter eines Modells und ist wesentlicher Bestandteil der Trainingsphase im Data Science Workflow. Das Ziel der Phase liegt darin, die Hyperparameter des gewählten Modells so anzupassen, dass die Ergebnisse am Ende optimal in Bezug auf die Anforderungen sind. Wie bereits im weiteren Artikel erläutert, fallen unter den Begriff Hyperparameter alle Parameter, die vor Durchlauf des eigentlichen Trainings bzw. Algorithmus des Lernverfahrens gesetzt werden und nicht direkt in Zusammenhang mit den verwendeten Daten stehen. Um die Hyperparameter eines Modells zu optimieren gibt es verschiedene Verfahren – dieser Artikel stellt die zwei wohl bekanntesten davon vor. Je nach Anwendungsfall können weitere Tuningmethoden sinnvoll sein, um die Ergebnisse in einem akzeptablen Zeitaufwand zu optimieren.
Random Search #
Wie es der Name bereits vermuten lässt, werden beim Random Search zufällige Kombinationen aus Hyperparametern ausprobiert und nach einer festgelegten Metrik evaluiert. Aus allen ausprobierten Variationen wird die Beste als finales Modell verwendet. Diese Methodik zwar relativ zeitsparend, wenn nur Modelle mit verhältnismäßig wenigen Kombinationen trainiert werden, liefert jedoch auch nicht zwingend das beste Ergebnis. Random Search kann allerdings gut zu Beginn des Tuning Prozesses eingesetzt werden, um einen ungefähren Einblick über optimale Parameter zu bekommen. Der folgende Codeblock zeigt wie mit der Implementierung von Sklearn ein Randomized Search durchgeführt werden kann. Zunächst muss eine verfügbare Auswahl an Parametern als Dictionary erstellt werden, aus dem sich der Suchalgorithmus dann im Suchverlauf zufällige Kombinationen auswählen kann. Nach der Suche können die optimalen Parameter abgerufen und angezeigt werden.
from sklearn.model_selection import RandomizedSearchCV
from sklearn.neighbours import KNeighboursClassifier
# Parameter für Suche setzen
params = {n_neighbours=list(range(25)), p=[1,2,3]}
# Suche starten
clf = RandomizedSearchCV(KNeighboursClassifier(), params)
clf.fit(X_train, y_train)
# Ergebnisse abrufen
print(clf.best_params_)Grid Search #
Ähnlich zum Random Search werden auch beim Grid Search zu testende Parameter in einem Python Dictionary festgehalten. Jedoch werden nicht zufällige, sondern alle verfügbaren Kombinationen aus Hyperparametern ausprobiert. Somit entsteht ein sogenanntes Param-Grid, das auch namensgebend für das Suchverfahren ist. Je nachdem wie viele Hyperparameter zur Auswahl gestellt werden, steigt die Anzahl der zu trainierenden Modelle sehr schnell an. Die Anzahl der Möglichkeiten berechnet sich, indem die Anzahl der Möglichkeiten der einzelnen Hyperparameter miteinander multipliziert werden. Bei einem Param-Grid von
param_grid = { C=[0.1, 1, 10], gamma=[1e-5, 1e-4, 1e-3 }
ergeben sich somit 3*3=9 verschiedene Kombinationsmöglichkeiten. Grid Search wird in den meisten Fällen mit der Cross Validation kombiniert, wodurch insgesamt noch mehr Modelle trainiert werden müssen. Der Vorteil liegt jedoch ganz einfach darin, dass aus den verfügbaren Kombinationen wirklich die optimalen Hyperparameter gefunden werden.
Die folgenden Grafiken visualisieren beispielhaft die Ergebnisse des Tunings einer Support Vector Machine unter Variation der Parameter C und Gamma und eines KNN-Modells unter Variation der Anzahl der Nachbarn.
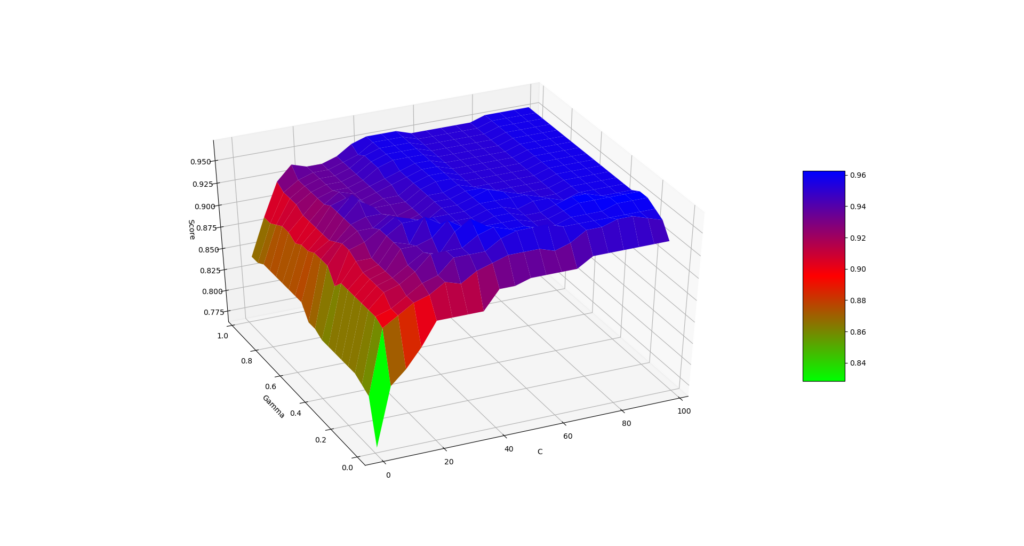
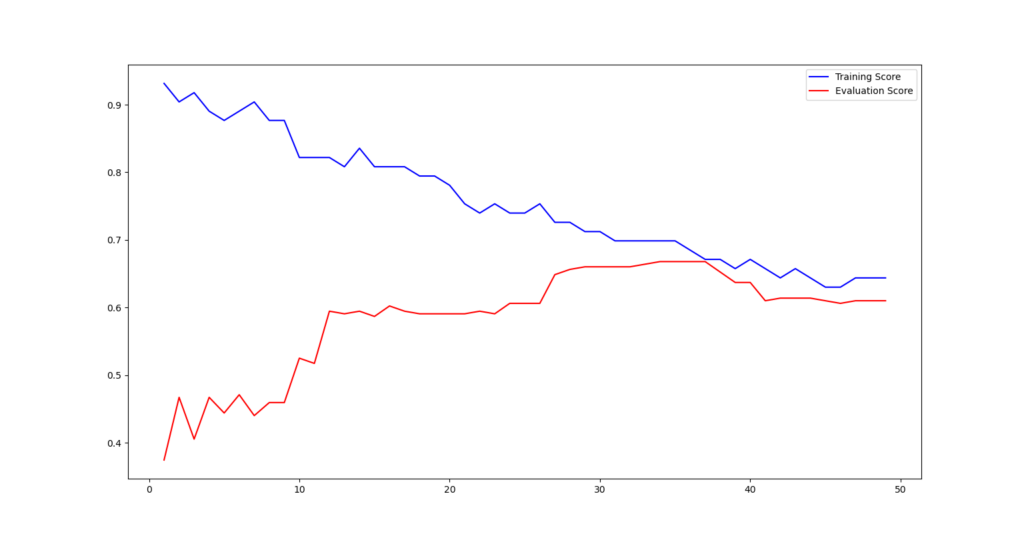
Weiterführend Links:
RandomizedSearchCV (Sklearn): https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html
GridSearchCV (Sklearn): https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
Hyperparameters Optimization: https://towardsdatascience.com/hyperparameters-optimization-526348bb8e2d



