
Frame Differencing ist eine Methode der klassischen Bildverarbeitung und macht Unterschiede zwischen zwei aufeinander folgenden Bildern (meist aus einem Video) sichtbar. Daher können bei einer statischen Kamera Perspektive sich bewegende Objekte erkannt werden. Generell ist aber die Genauigkeit der erkannten Objekte wesentlich geringer, als etwa bei CNN basierten Methoden der Objekterkennung, wie etwa YOLOv4. Frame Differencing bietet jedoch den Vorteil, das es weitaus weniger Rechenleistung erfordert. Die Funktionsweise basiert auf simplen mathematischen Operationen, die mehr oder weniger unabhängig von der Leistungsfähigkeit eines Prozessors in Echtzeit mit mehr als 30 FPS durchgeführt werden können. Dieser Artikel erklärt nachfolgend die Funktionsweise von Frame Differencing und stellt die Umsetzung in Python mit der Open-CV Bibliothek vor.
Funktionsweise #
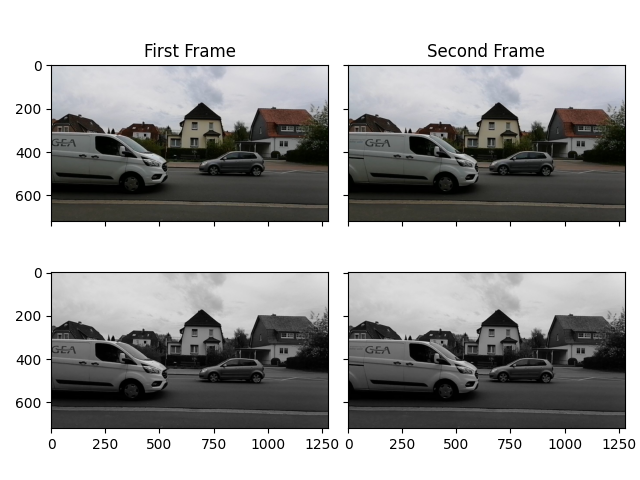
Ausgangslage für Frame Differencing sind zwei Bilder, die in einem zweitlichen Zusammenhang zueinander stehen (Methodik kann auch ohne Abfolge der Bilder angewandt werden, wird aber keine sinnvollen Ergebnisse liefern) und direkt aufeinander folgen – wie etwa zwei Frames in einem Video. Im ersten Schritt werden die Bildern in die Grauwertdarstellung umgewandelt, da farbliche Informationen grundsätzlich weniger relevant sind. Die Abbildungen zeigen Aufnahmen einer Straße mit vorbeifahrenden Fahrzeugen – oben die Originalbilder und unten die transformierten Bilder.

Zwischen den beiden Grauwertbildern kann im zweiten Schritt für jeden Pixel die absolute Differenz berechnet werden. Diese liegt zwischen 0 und 255 und gibt entsprechend wieder ein Grauwertbild zurück. Um nur relevante Unterschiede zu betrachten, wird zusätzlich ein binärer Filter angewandt. Alle Pixel die überhalb einer festgelegten Schwelle liegen (heißt der Pixelwert ist höher als die Schwelle), wird der Wert auf 255 gesetzt und der Pixel wird entsprechend weiß. Liegt der Wert unter der Schwelle, wird der Pixel auf 0 gesetzt und damit schwarz. Die Auswirkung des Filters ist in der obigen Abbildung gut zu erkennen.
Im dritten und letzten Schritt kann durch Dilatation die Kontur der Differenzen deutlicher gemacht werden, um anschließend etwa Flächen und damit Objekte erkennen zu können. Für jeden weißen Pixel werden angrenzende Pixel ebenfalls auf weiß gesetzt und Kanten werden vergrößert. Diese Methodik wird in der Bildverarbeitung meist genutzt, um dünne Kanten “sichtbarer” zu machen.

Realisierung in Python #
Der vollständige Code zu den Abbildungen kann unter folgendem Link eingesehen werden:
https://github.com/LG4ML/Wiki_Figures/blob/master/Computer%20Vision/FrameDifferencing.py
# Import the Open-CV library
import cv2
# Load two consecutive frames (replace the path)
frame1 = cv2.imread('path_to_image_1')
frame2 = cv2.imread('path_to_image_2')
# Convert frames to grayscale
frame1_gray = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
frame2_gray = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
# Calculate difference and apply threshold
abs_difference = cv2.absdiff(frame1_gray, frame2_gray)
_, binary = cv2.threshold(abs_difference, 50, 255, cv2.THRESH_BINARY)
# Apply dilation
dilated = cv2.dilate(binary, kernel=np.ones((3, 3), dtype=np.int8), iterations=15)
Weiterführende Links:
– Moving Object Detection using Frame Differencing: https://debuggercafe.com/moving-object-detection-using-frame-differencing-with-opencv/
– Frame differencing with post-processing techniques: https://ieeexplore.ieee.org/abstract/document/5759867
– Object Tracking – Frame Differencing: https://www.youtube.com/watch?v=kMa2hIXs2yY



