
Data Augmentation meint die Veränderung von bestehenden Daten, um mehr Variation in die Trainingsdaten zu bekommen und damit Overfitting der Machine Learning Modelle zu vermeiden. Gerade bei kleinen Datensätzen kann durch Data Augmentation mehr oder weniger ein “größerer” Datensatz simuliert werden, da sich Input Daten durch die leichte Veränderung zwar ähnlich sind, aber nicht mehr identisch. Somit können Modelle nicht direkt einzelne Samples auswendig lernen, sondern müssen generalisieren und die wichtigen Merkmale extrahieren bzw. lernen. Data Augmentation kann viele verschiedene Formen haben, die im Wesentlichen durch die Art der Daten eingegrenzt bzw. festgelegt wird. In diesem Artikel werden verschiedene Methoden der Data Augmentation vorgestellt.
Bilder #
Gerade in der Klassifikation oder Segmentierung von Bildern sind die Neuronalen Netzwerke derart komplex, dass die Variation der Trainingsdaten durch Data Augmentation eine wichtige Rolle spielt. Ohne Data Augmentation neigen vor allem beim Transfer Learning Netze wie bspw. ResNet-50 sehr schnell zum Overfitting und lernen aufgrund der hohen Anzahl an Parametern alle Samples auswendig. Für Bilddaten gibt es ein breites Spektrum an Methoden zur Veränderung des originalen Inputbildes, wie die folgende Abbildung gut verdeutlicht.

Die Data Augmentation kann entweder vor Beginn jeder Epoche auf die Trainingsdaten angewandt oder alternativ direkt in das Modell integriert werden. Bei letzterem werden verschiedene Layer verwendet, die etwa Operationen wie zufällige Rotation oder Skalierung auf den eingehenden Bilddaten vornehmen. Am meisten genutzt wird neben Rotation und Skalierung bzw. Cropping noch das Spiegeln entlang der horizontalen oder vertikalen Achse.
Zeitreihen #
Zeitreihen haben eine komplett andere Beschaffenheit bzw. Form als Bilder und dementsprechend auch andere Methoden für die Data Augmentation. Wichtig ist dabei, dass die grundlegende Form der Zeitreihe erhalten bleibt und Proportionen nicht übermäßig verändert werden. Beispielsweise würde es keinen Sinn machen, bei einem insgesamt fallenden Aktienkurs durch Cropping (wie bei Bildern) einen kleinere Ausschnitt zu betrachten. In diesem könnte der Kurs kurzfristig steigen und damit falsche Informationen ermitteln. Daher sollte die Zeitreihe immer als Ganzes behandelt werden und entsprechend bestehen bleiben. Nachfolgend werden zwei simple Methoden, die in der Abbildung verdeutlich werden, weiter erläutert.
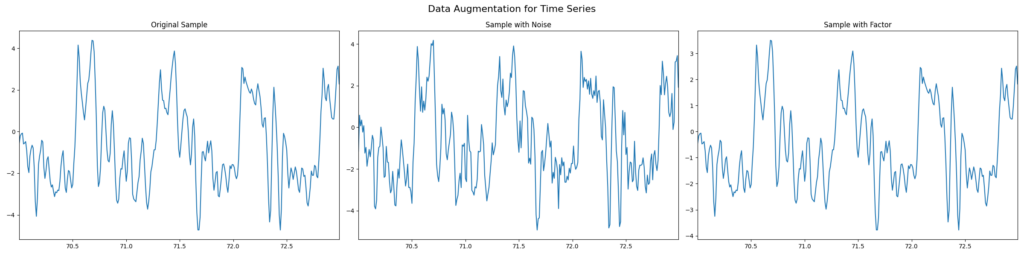
- Hinzufügen von Noise: Auf jeden einzelnen Punkt der Zeitreihe werden Werte addiert, die aus einer Normalverteilung mit dem Mittelwert 0 stammen. Die Standardabweichung der Verteilung muss je nach Problemstellung gewählt werden, da nicht immer das gleiche Maß an Streuung benötigt wird. Bei kleinen Wertebereichen in der Zeitreihe würde ein zu großes Sigma bewirken, dass die Zeitreihe ihre generelle Form verliert und Zusammenhänge verloren gehen. Ein zu kleines Sigma dagegen würde zu Geringe Unterschiede bewirken, die Overfitting nicht verhindern könnten.
- Streckung & Stauchung: Eine zweite Möglichkeit ist die Multiplikation der gesamten Zeitreihe mit einem festen Faktor, der aus einer Normalverteilung mit dem Mittelwert 1 gezogen wird. Ist der Faktor größer als 1 resultiert daraus eine Streckung, andernfalls wird die Zeitreihe gestaucht. In beiden Fällen bleiben die Zusammenhänge und Verläufe exakt erhalten, jedoch verändert sich der Wertebereich.
Text #
Für Data Augmentation auf Textdaten werden noch einmal gänzlich andere Methoden benötigt, da es sich nicht um numerische Daten handelt bzw. Text nicht sinnvoll als Zahlen dargestellt werden kann. Zur Veränderung von Sätzen gibt es unter anderem die folgenden Möglichkeiten:
- Übersetzung: Der Satz wird in eine andere Sprache und anschließend zurück übersetzt. Dadurch werden Struktur und Wörter geändert und die Sätze sind nicht identisch.
- Synonyme: Wörter werden durch ein Synonym mit der gleichen Bedeutung ersetzt.
- Ergänzen & Löschen: Der Satz wird verändert, indem zufällig ein Synonym eingefügt oder ein Wort gelöscht wird.
Nach der Augmentation können die Sätze mit Verfahren wie Bag-of-Words oder Word Embedding in eine Zahlendarstellung umgewandelt und von Machine Learning Modellen verarbeitet werden.
Audio #
Audiosignale sind grundsätzlich ebenfalls Zeitreihen und können mit den obenstehenden Methoden der Data Augmentation transformiert werden. Wird das Audiosignal jedoch als Spektrogram dargestellt, gibt es eine andere Möglichkeit der Transformation. Das SpecAugment Verfahren funktioniert wie folgt:
- Die Spektrogramme werden standardisiert, wodurch der Mittelwert auf 0 gesetzt wird und die Standardabweichung bei 1 liegt.
- Aus den verfügbaren Frequenzbereichen werden n zufällig ausgewählt, wobei n als Parameter optimiert werden muss.
- Die Werte der gewählten Bereiche werden auf 0 (den Mittelwert) gesetzt und damit quasi “abgeschaltet”.
Durch dieses Vorgehen verhindert, dass Machine Learning Modelle nur einzelne Bereiche für die Entscheidungsfindung heranziehen, sondern die gesamten verfügbaren Informationen.
Weiterführende Links:
– What is Data Augmentation?: https://research.aimultiple.com/data-augmentation/
– Data Augmentation in NLP: https://neptune.ai/blog/data-augmentation-nlp
– SpecAugment: https://arxiv.org/abs/1904.08779v2



