
Distanzmetriken oder auch Distanzmaße werden verwendet, um die Ähnlichkeit von Daten(-punkten) zu bestimmen und einen Vergleich zu ermöglichen. Statt Ähnlichkeit von Daten spricht man dabei auch häufig vom Abstand. Distanzmaße bilden die basis für alle distanzbasierten Verfahren, wie etwa K-Nearest-Neighbour als Klassifikationsverfahren oder auch SMOTE (Syntetic Minority Class Oversampling Technique) aus dem Bereich des Sampling. Die Auswahl des Distanzmaßes spielt jeweils eine wichtige Rolle und wird im letzten Teil dieses Beitrags kurz näher erläutert.
Wichtige Distanzmaße #
Nachfolgend werden vier wichtige verschiedene Distanzmaße vorgestellt:

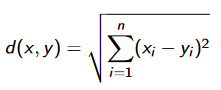
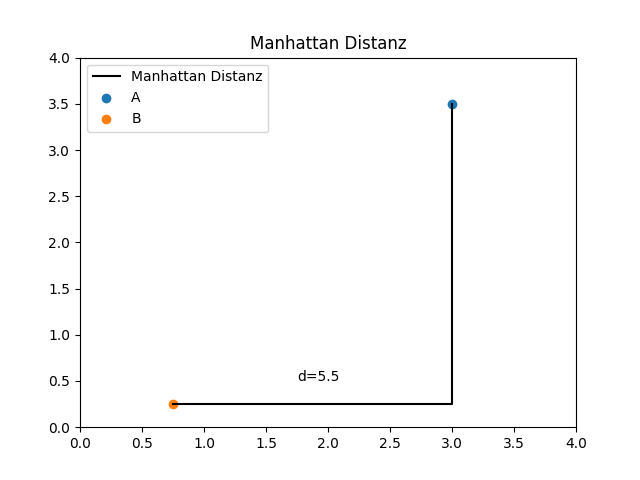

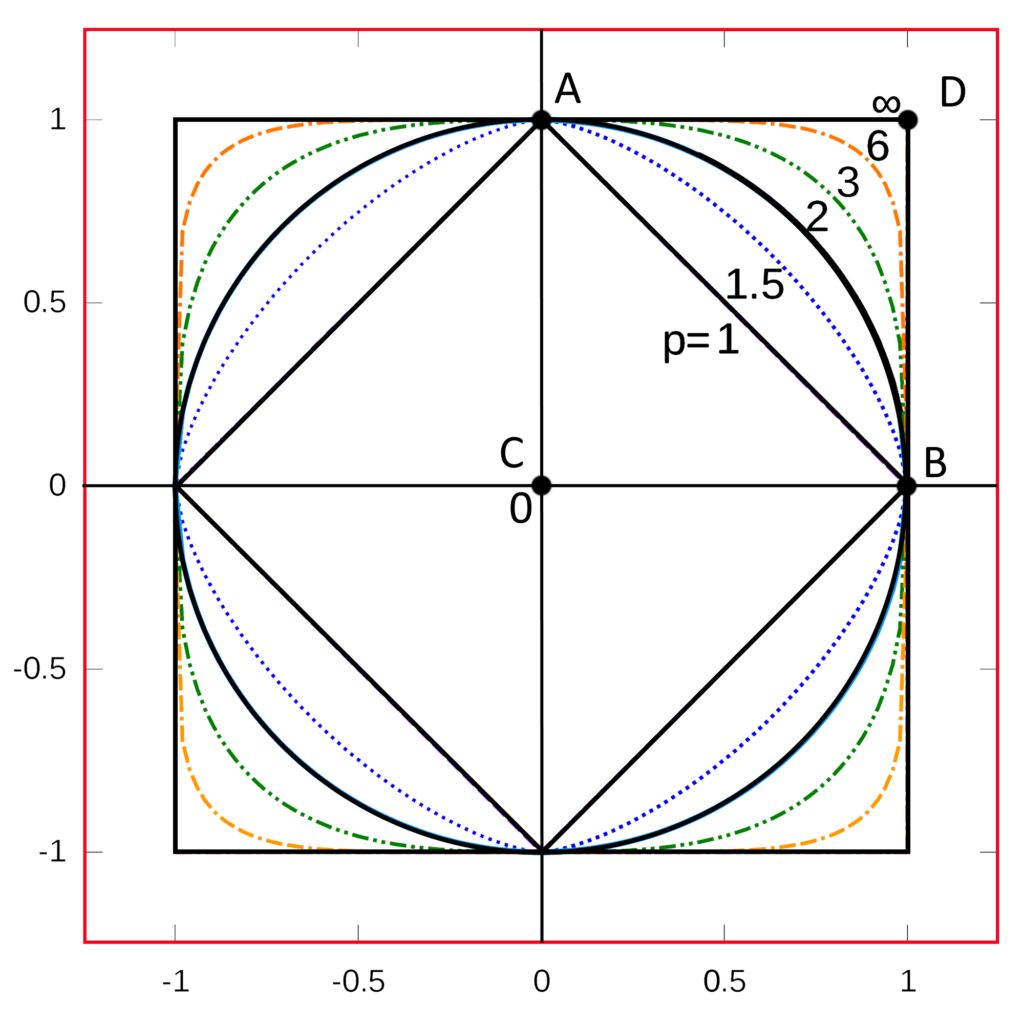
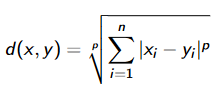

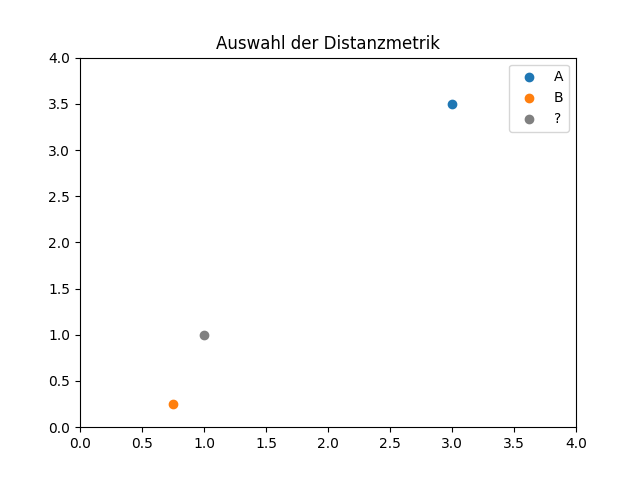
Auswahl der richtigen Distanzmetrik #
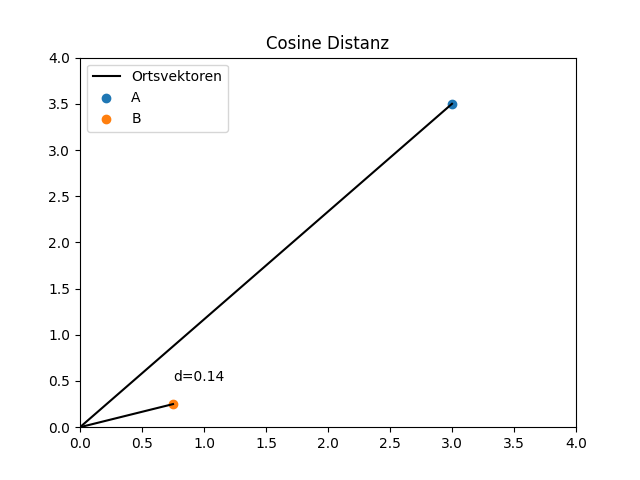
Die Auswahl der Distanzmetrik spielt eine wichtige Rolle, da sie maßgeblich die Ergebnisse von distanzbasierten Verfahren beeinflusst. Im Beispiel ermittelt werden, ob Punkt A oder B ähnlicher sind zum neuen grauen Punkt. Bei Auswahl von Manhattan oder Euklidischer Distanz word B als ähnlicher eingestuft, bei Auswahl der Cosine-Distanz jedoch Punkt A.
Daher sollte immer überprüft werden, ob eine bestimmte Distanzmetrik für die Problemstellung geeignet ist und ob die Ergebnisse mit den Erwartungen übereinstimmen.
Weiterführende Links #
17 Types of Similarity and Dissimilarity Measures: https://towardsdatascience.com/17-types-of-similarity-and-dissimilarity-measures-used-in-data-science-3eb914d2681
How to decide the perfect distance metric: https://towardsdatascience.com/how-to-decide-the-perfect-distance-metric-for-your-machine-learning-model-2fa6e5810f11



