
Die Data Exploration (zu deutsch: Datenexploration) bezeichnet den klassischen ersten Schritt in Datenanalyse-Projekten. Hierbei untersuchst du deinen ausgewählten Datensatz zunächst auf unstrukturierte Weise, um erste Muster und interessante Merkmale in den Daten aufdecken zu können. Die Data Exploration dient nicht dazu, alle Informationen oder Erkenntnisse von einem Datensatz direkt aufzuzeigen. Vielmehr sollst du hierrüber einen ersten Einblick in deinen Datensatz bekommen, um die Daten besser verstehen und folglich auch präziser und zielgerichteter in nachfolgenden Schritten untersuchen und analysieren zu können. Noch wichtiger ist es, dass du dir in Zuge dessen eine gewisse Vertrautheit mit den vorhandenen Daten aufbaust, die die Suche nach wertvollen Erkenntnissen wesentlich vereinfacht.
In vielen Fällen werden bei der Data Exploration Visualisierungen verwendet, da sie einen einfacheren Überblick über deinen Datensatz bieten als die manuelle, „unvisualisierte“ Untersuchung von Tausenden und Abertausenden Zahlen, Namen, Datenpunkten etc. Mithilfe einiger Zeilen Code und den Einsatz von Visualisierungen ist die Data Exploration sehr einfach, hilfreich und interessant. Im Folgenden schauen wir uns gemeinsam die Data Exploration für ein beispielhaftes Datenanalyse-Projekt an.
Automatische Analyse mit Pandas Profiling #
Für eine einfache Data Exploration empfehlen wir dir die Pandas-Bibliothek für Python. Pandas ist das wichtigste Werkzeug, das Datenwissenschaftler zum Erforschen und Bearbeiten von Daten verwenden.
Der wichtigste Teil der Pandas-Bibliothek ist das DataFrame. Ein DataFrame ist eine Art Tabelle und vergleichbar mit klassischen Excel-Tabellen. Im Gegensatz zu normalen Excel-Tabellen stehen uns mit Dataframes jedoch eine Vielzahl an Datenanalyse-Werkzeugen direkt zur Verfügung (Diese lernst du im zweiten Beispiel in diesem Beitrag kennen). Als erstes Beispiel für die Data Exploration werden wir uns ein in der Data-Science-Welt bekannten Datensatz, den Titanic-Datensatz ansehen und analysieren. Dieser Datensatz enthält eine Vielzahl an Informationen rund um das Titanic-Unglück.
Wenn wir einen Datensatz in ein Pandas Dataframe einlesen, sieht es wie die folgende Tabelle aus:

Wir haben schonmal eine Tabelle, die wir nun mithilfe der Bibliothek Pandas Profiling automatisch analysieren lassen. Pandas Profiling ist eine Analytics-Bibliothek für Python auf Basis von Pandas und erleichtert immens die Data Exploration. Im folgenden zeigen wir dir den Beispiel Code für eine Data Exploration mit Pandas Profiling (es sind nur ein paar Zeilen Code):
# Benötigte Bibliotheken importieren
from pandas_profiling import ProfileReport
import pandas as pd
# Einlesen des Datensatzes
data = pd.read_csv('titanic.csv')
# Report in Variable speichern
report = ProfileReport(data)
# Report exportieren
report.to_file(output_file='report.html')
Der Report wird als HTML-Datei exportiert (an den Dateispeicherort, wo sich auch dein Datensatz befindet). Diesen kannst du einfach im Browser öffnen.
Wir erhalten eine umfassende Übersicht über den Datensatz.

Wir können direkt sehen, dass der Titanic-Datensatz insgesamt 12 Features (Spalten in der Tabelle) und 891 Zeilen beinhaltet. Außerdem sehen wir, dass nicht alle Zellen in der Tabelle Daten beinhalten. Anscheinend sind ca. 8% des Datensatzes mit leeren Werten gefüllt.
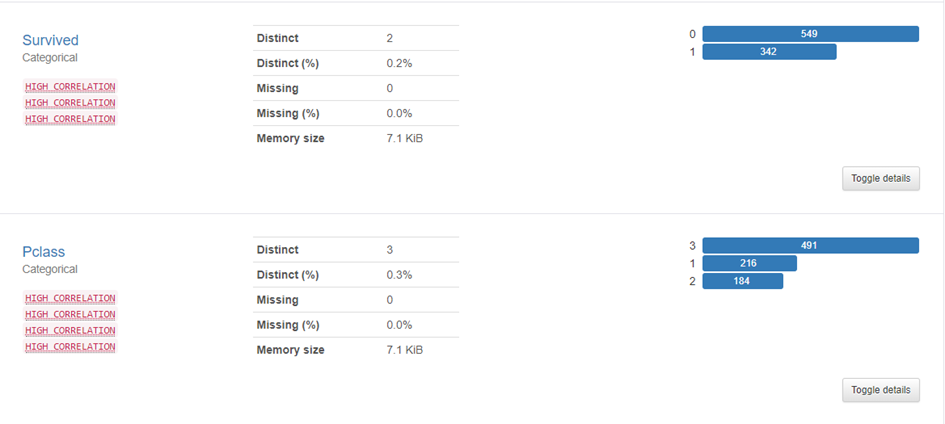
Weiterhin sehen wir, dass insgesamt 549 Personen gestorben sind und 342 überlebt haben. Pclass gibt die einzelnen Klassen an, die Passagiere buchen konnten. Hier sehen wir, dass 216 Personen die erste Klasse gebucht haben. Im Gegensatz dazu haben 491 Personen die günstigste, dritte Klasse gebucht.

Darüber hinaus sehen wir hier, dass ca 35% der Passagiere weiblich und 65% männlich waren. Auffällig ist auch die hohe Anzahl an Babys (0 bis ca. 3 Jahre) und Personen zwischen 20 und 40. Es sind wenig Ältere an Bord gewesen.
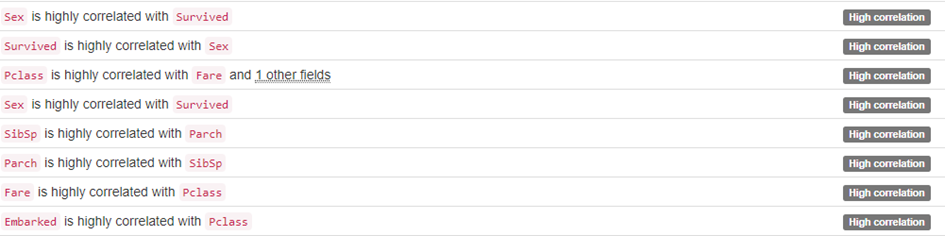
Außerdem gibt uns Pandas Profiling einen Überblick über Korrelationen zwischen den unterschiedlichen Features. Hier sehen wir, dass beispielsweise das Geschlecht anscheinend stark mit der Überlebensrate zusammenhängt. Das werden wir uns unter anderem in der Selbständigen Analyse genauer anschauen.
Tiefergehende Analysen mit Pandas #
Wir haben mithilfe der automatischen Analyse unter Verwendung von Pandas Profiling bereits einen umfassenden Einblick in den Datensatz bekommen. Nun gehen wir ein Stück weiter und analysieren selbständig den Datensatz. Wir haben bereits aufgrund der Pandas Profiling Analyse bereits gesehen, dass Geschlecht und Überlebensrate stark zusammenhängen. Schauen wir uns das mal genauer an. Folgenden Code verwenden wir zum Einlesen des Datensatzes, speichern des Datensatzes in ein Pandas Dataframe und ausgeben der ersten Zeilen des Datensatzes:
# Importieren benötigter Bibliotheken
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Festlegen der Visualisierungseinstellungen (Nicht unbedingt nötig)
plt.style.use(style='ggplot')
plt.rcParams['figure.figsize'] = (10, 6)
# Einlesen des Datensatzes
data = pd.read_csv('titanic.csv')
# Ausgabe der ersten Zeilen des Datensatzes
data.head()

Der Datensatz sieht aus wie in der Abbildung visualisiert. Nun kennen wir auch die Feature Namen, mit denen wir nun Charts ausgeben können. Wie bereits erwähnt wollen wir uns einmal den Zusammenhang von Geschlecht und Überlebensrate anschauen. Diesen Zusammenhang visualisieren wir mit der Chart-Bibliothek Seaborn für Python ( import seaborn as sns ). Folgenden Code verwenden wir für die Visualisierung:
# Ausgabe eines Geschlecht/Überlebensrate-Charts in Form eines Spaltendiagramms
sns.countplot(x='Pclass', hue='Survived', data=data)
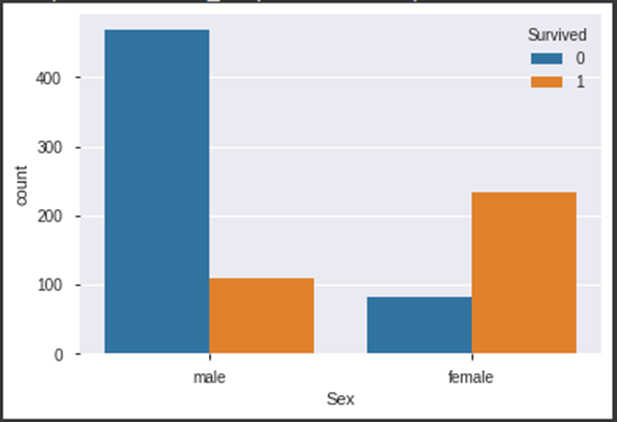
Hier sehen wir, dass die Überlebensrate von Frauen gegenüber männlichen Passagieren deutlich erhöht ist (0 steht für „Nicht überlebt“, 1 steht für „Überlebt“).
Du kannst dir vielleicht denken, dass die Klasse, die eine Person gebucht hat, auch mit der Überlebensrate zusammenhängt. Visualisieren wir einmal ein Klasse/Überlebensrate-Chart mit folgendem Code:
# Ausgabe eines Klasse/Überlebensrate-Charts in Form eines Spaltendiagramms
sns.countplot(x='Pclass', hue='Survived', data=data)

Der Chart zeigt, dass Passagiere der dritten Klasse eine sehr niedrige Wahrscheinlichkeit hatten, das Titanic Unglück zu überleben. 120 Personen der ersten Klasse haben überlebt, 350 Personen sind gestorben. Dem gegenüber steht die erste (und teuerste) Klasse: Ungefähr 140 Personen der ersten Klasse haben überlebt, ungefähr 80 sind gestorben.
Wir gehen noch einen letzten Schritt weiter. Schauen wir uns einmal die Anzahl an Familienmitglieder auf der Titanic an und grenzen den Datensatz auf Frauen und erste Klasse ein mit folgendem Code:
# Visualisierung der Überlebensrate von Frauen und Männern der ersten Klasse
sns.countplot(x='Sex', hue='Survived', data=data[data.Pclass==1]) 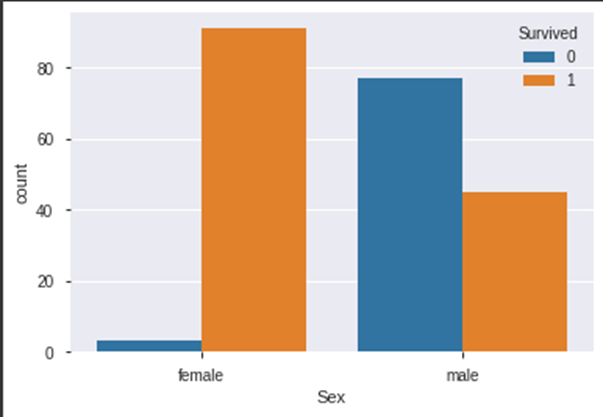
Wir sehen hier, dass vor allem Frauen gegenüber den Männern eine sehr hohe Überlebenschance innerhalb der ersten Klasse hatten. Schauen wir uns einmal die dritte Klasse an:
# Visualisierung der Überlebensrate von Frauen und Männern der dritten Klasse
sns.countplot(x='Sex', hue='Survived', data=data[data.Pclass==3]) 
Hier ist die Überlebenschance von Frauen ungefähr 50/50, die von Männern sehr niedrig.
Weiterführende Informationen #
Du siehst, dass die Data Exploration dir einen umfassenden und auch tiefen Einblick in einen Datensatz geben kann. Versuche es doch einmal selbst, entweder mit dem Titanic Datensatz oder einem andern. Hierfür findest du im Folgenden weitere Informationen:
Titanic-Datensatz: https://www.kaggle.com/c/titanic/data
Immobilienpreise in Melbourne, Australien-Datensatz: https://www.kaggle.com/dansbecker/melbourne-housing-snapshot
Weiteres zu Pandas Profiling: https://medium.com/nerd-for-tech/pandas-profiling-4cc99cbc0df5#:~:text=Pandas%20Profiling%20is%20an%20incredible,a%20set%20of%20correlation%20tools.
Weiteres zu Data Exploration mit Pandas und Python: https://towardsdatascience.com/data-exploration-101-with-pandas-e059d0661313



