

Decision Trees oder auch zu deutsch Entscheidungsbäume sind eine baumartige Struktur, die sogenannte Entscheidungsregeln abbilden und damit gut für Klassifikationsprobleme geeignet sind. Diese Regeln leiten sie auf Basis von Features und zugehörigen Labels ab, wodurch sie in den Bereich des überwachten Lernens fallen. Die Komplexität der Bäume hängt dabei stark von der Problemstellung und vor allem der Anzahl der Feature ab, die überhaupt erst Entscheidungen ermöglichen. Die wesentlichen Bestandteile eines Entscheidungsbaumes sind:
Bestandteile von Entscheidungsbäumen #
- Knoten: Die Knoten sind der wichtigste Teil der Bäume und bilden die Entscheidungsregeln ab. So kann in einem Knoten bspw. geprüft werden, ob das Alter einer Person älter als 18 Jahre ist oder nicht. Je nach Art der Splits wird entweder in genau zwei Bereiche aufgeteilt (Binary Splits) oder mehrere Bereiche – im Falle des Alters zum Beispiel unter 18 Jahren, zwischen 18 und 30 Jahren oder älter als 30 Jahre.
- Äste: Die Äste stellen die Verbindung zwischen zwei Knoten dar und spannen somit den Baum auf. Je komplexer das Problem, desto mehr Knoten und entsprechend auch Äste werden benötigt.
- Blätter: Blätter sind am Ende eines Astes zu finden, wenn keine weiteren Entscheidungen mehr getroffen werden muss und ein Element aufgrund der Kombination an Entscheidungen eindeutig identifiziert werden kann. Die Blätter sind jeweils immer mit genau einer Klasse verbunden.
- Wurzel: Die Wurzel bildet den Anfang des Baumes und ist genau genommen der erste Entscheidungsknoten. Im Gegensatz zu Bäumen in der Realwelt ist die Wurzel bei Entscheidungsbäumen oben zu finden, entsprechend sind die Blätter unten am Baum.
Aufspannen von Bäumen #
Wie wird ein Decision Tree aufgebaut?
Beim Training eines Decision Trees werden die verfügbaren Attribute in Bezug auf den Informationsgehalt hin geordnet und nach und nach für Entscheidungen herangezogen, bis der Baum vollständig aufgespannt ist. Dabei kann die sogenannte Entropie verwendet werden, die ein Maß zur Charakterisierung der Unreinheit einer Menge ist. Als Alternative bieten viele Algorithmen die Gini Option an, die eine weitere Option ist, Attribute in Bezug auf ihre Informationen hin zu bewerten.
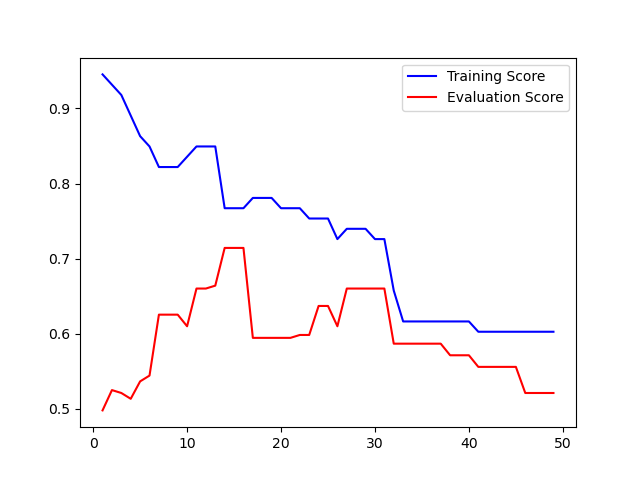
Das Aufspannen der Entscheidungsbäume kann über die Hyperparameter gesteuert und begrenzt werden. In viele Fällen ist es sinnvoll, die Tiefe des Baumes zu begrenzen, sprich die maximale Länge zu den Blättern zu reduzieren. Dieser Vorgang wird auch als Pruning (Beschneiden) bezeichnet.
Über das Optimieren der Hyperparameter können je nach Bedürfnissen an das Modell die Ergebnisse entsprechend angepasst werden.
Decision Trees bringen den Vorteil mit sich, dass sich die Entscheidungsregeln gut visualisieren lassen und damit die Entscheidungsgrundlage sowie die wichtigsten Attribute einfach ersichtlich sind. Sie sind schnell zu implementieren und können kombiniert sogenannte Entscheidungswälder (engl. Random Forest) bilden, um auch komplexe Klassifikationsaufgaben lösen zu können.
Weiterführende Links:
How Decision Trees Make Decisions: https://towardsdatascience.com/entropy-how-decision-trees-make-decisions-2946b9c18c8
Sklearn DecisionTreeClassifier: https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html



